Chapter 5 Data visualization using Python
5.1 Introduction
Data visualization is a basic task in data exploration and understanding. Humans are mainly visual creatures, and data visualization provides an opportunity to enhance communication of the story within the data. Often we find that data and the data-generating process is complex, and a visual representation of the data and our innate ability at pattern recognition can help reveal the complexities in a cognitively accessible way.
5.1.1 An example gallery
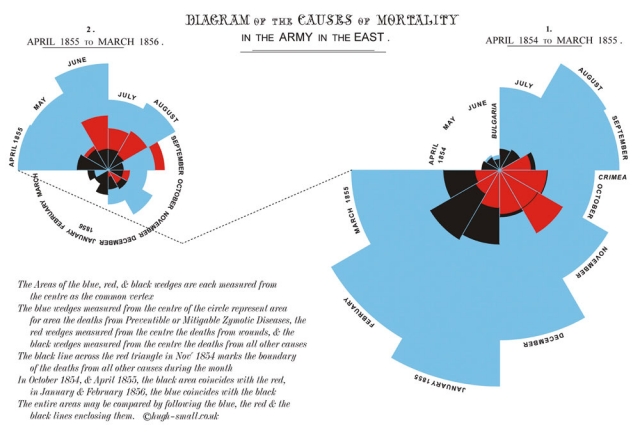
Data visualization has a long and storied history, from Florence Nightangle onwards. Dr. Nightangle was a pioneer in data visualization and developed the rose plot to represent causes of death in hospitals during the Crimean War.
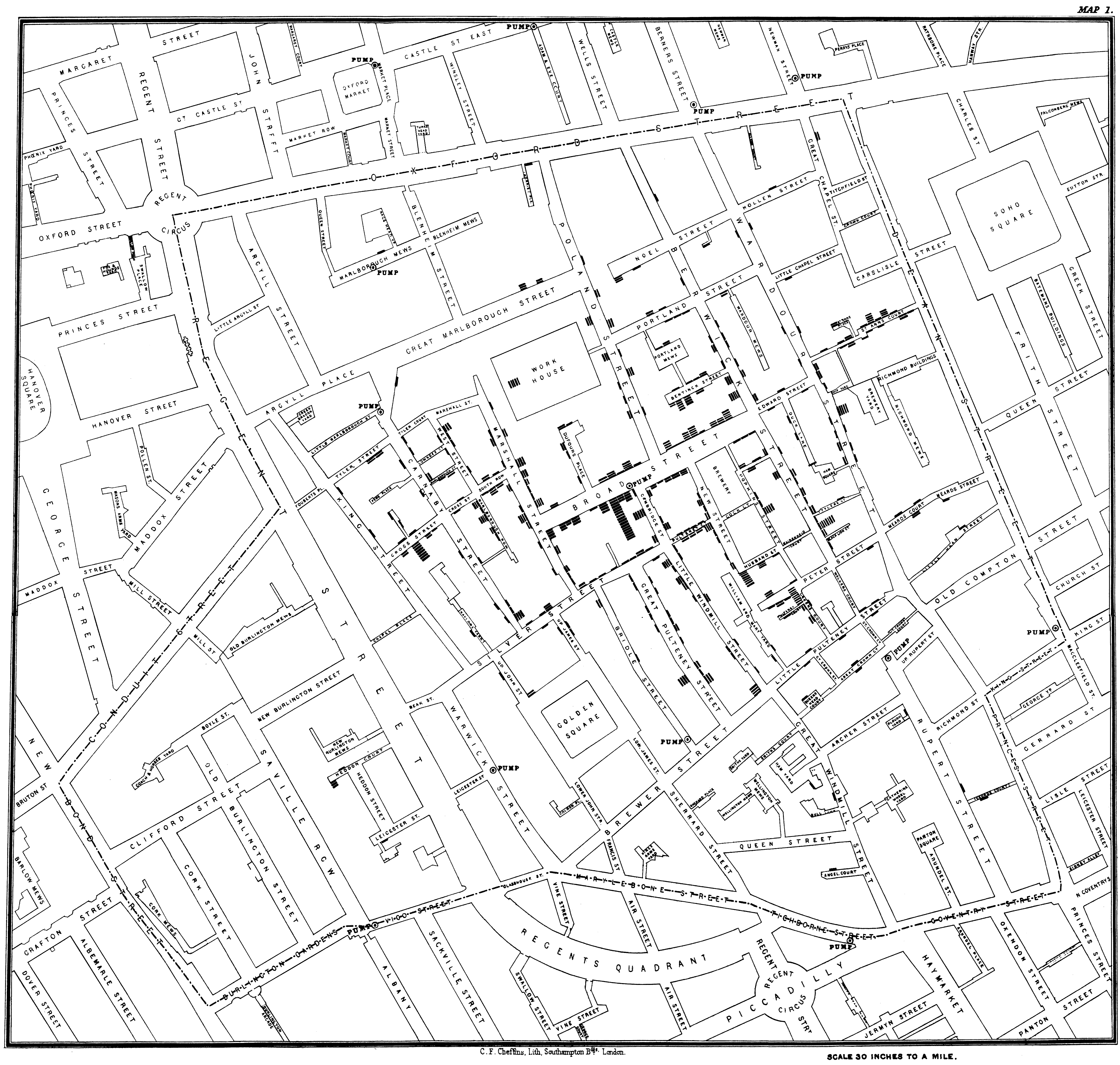
John Snow, in 1854, famously visualized the cholera outbreak in London, which showed the geographic proximity of cholera prevalence with particular water wells.
In one of the more famous visualizations, considered by many to be an optimal use of display ink and space, Minard visualized Napoleon’s disastrous campaign to Russia

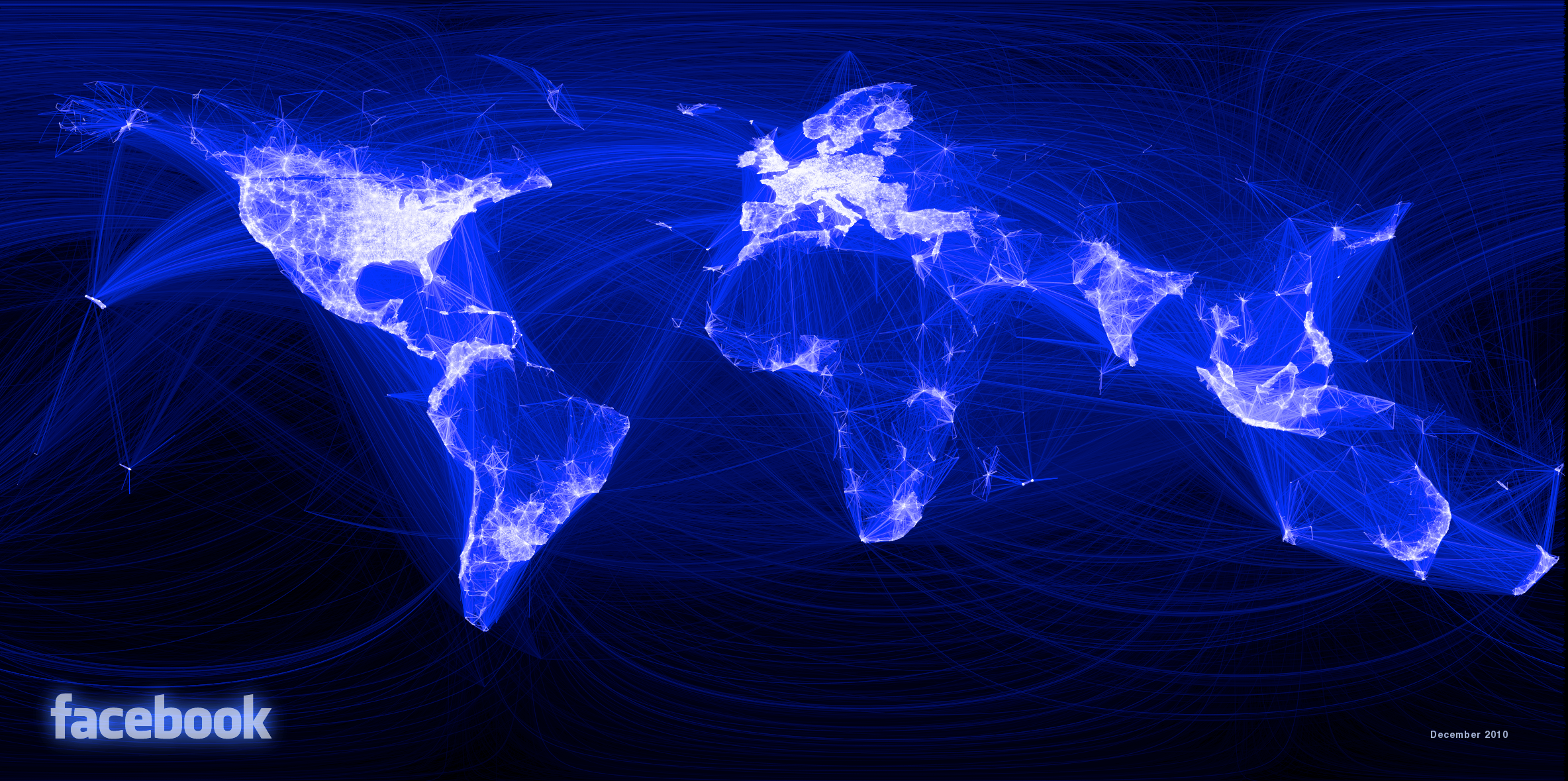
In more recent times, an employee at Facebook visualized all connections between users across the world, which clearly showed geographical associations with particular countries and regions.
5.1.2 Why visualize data?
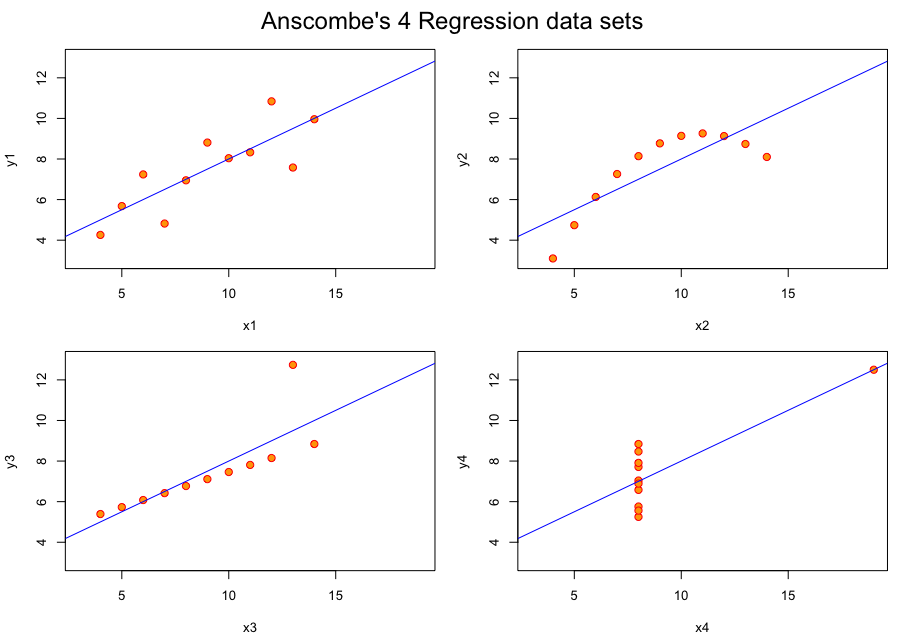
We often rely on numerical summaries to help understand and distinguish datasets. In 1973, Anscombe published an influential set of 4 datasets, each with two variables and with the means, variances and correlations being identical. When you graphed these data, the differences in the datasets were clearly visible. This set is popularly known as Anscombe’s quartet.
A more recent experiment in data construction by Matejka and Fitzmaurice (2017) started with a representation of a dinosaur and created 10 more bivariate datasets which all shared the same univariate means and variances and the same pairwise correlations.
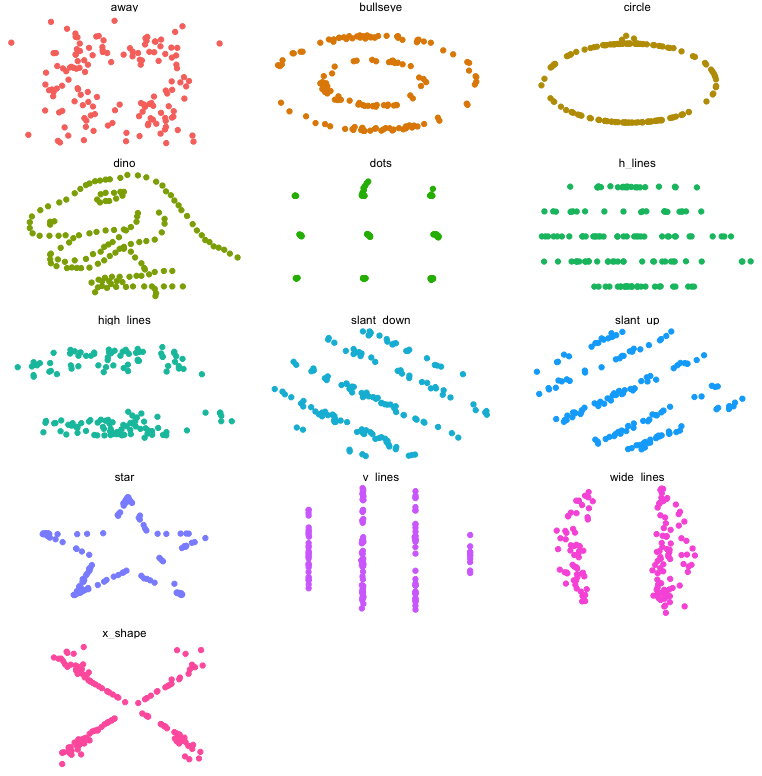
These examples clarify the need for visualization to better understand relationships between variables.
Even when using statistical visualization techniques, one has to be careful. Not all visualizations can discriminate between statistical characteristics. This was also explored by Matejka and Fitzmaurice.
| Strip plot | Boxplot | Violin plot |
|---|---|---|
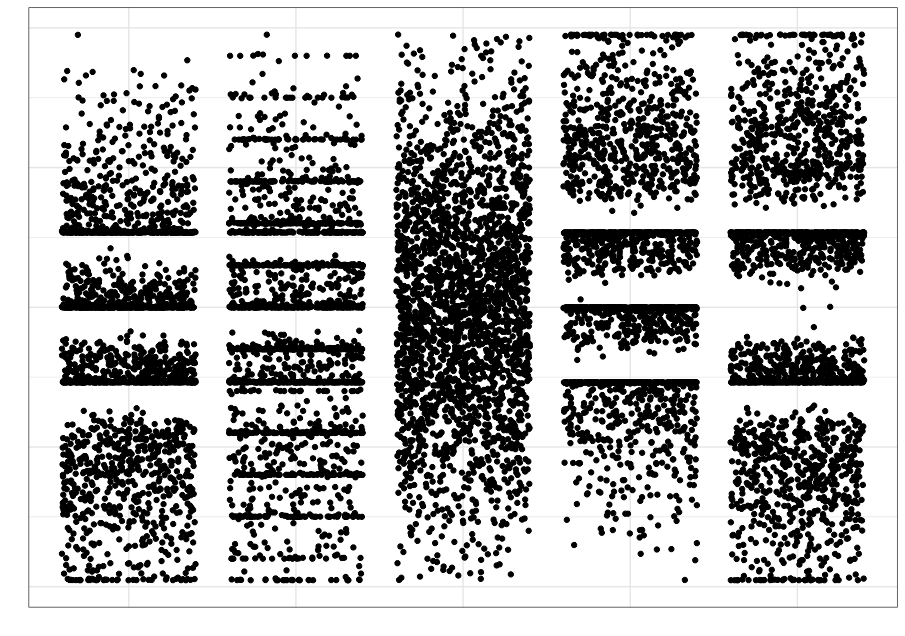 |
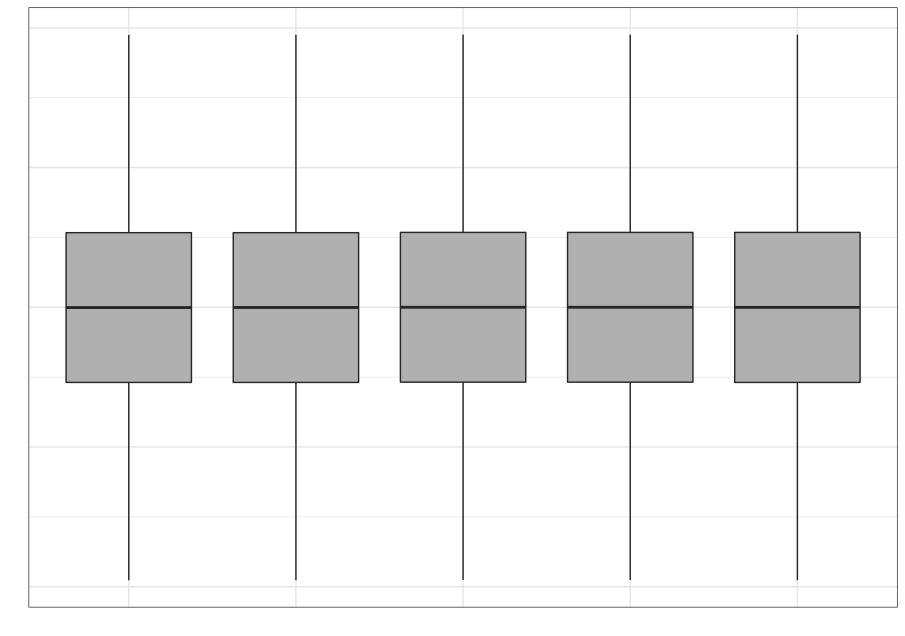 |
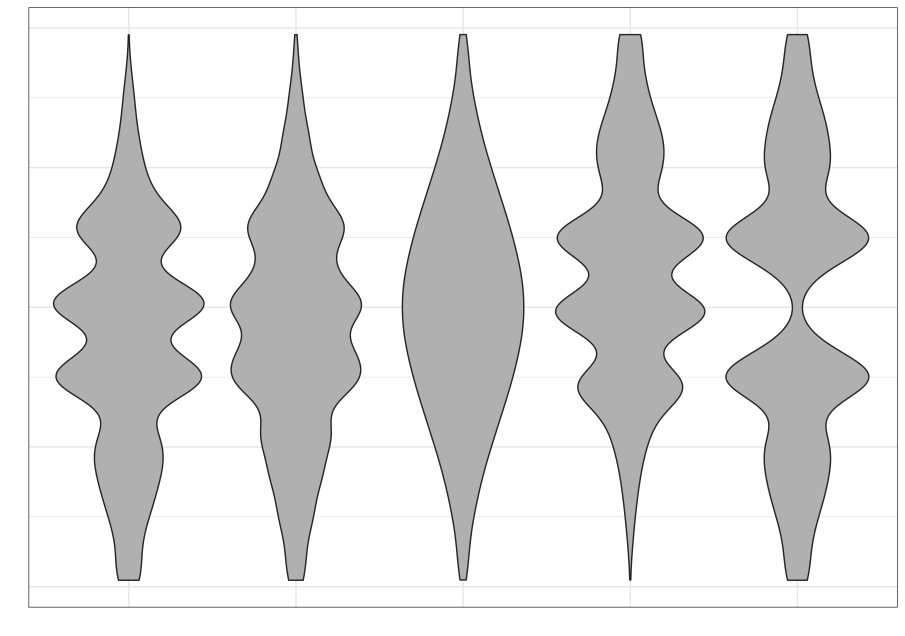 |
5.1.3 Conceptual ideas
5.1.3.1 Begin with the consumer in mind
- You have a deep understanding of the data you’re presenting
- The person seeing the visualization doesn’t
- Develop simpler visualizations first that are easier to explain
5.1.3.2 Tell a story
- Make sure the graphic is clear
- Make sure the main point you want to make “pops”
5.1.3.3 A matter of perception
- Color (including awareness of color deficiencies)
- Shape
- Fonts
5.1.3.4 Some principles
- Data-ink ratio
- No mental gymnastics
- The graphic should be self-evident
- Context should be clear
- Is a graph the wrong choice?
- Focus on the consumer
See my slides for some more opinionated ideas
5.2 Plotting in Python
Let’s take a very quick tour before we get into the weeds. We’ll use the mtcars dataset as an exemplar dataset that we can import using pandas
5.2.1 Static plots
We will demonstrate plotting in what I’ll call the matplotlib ecosystem. matplotlib is the venerable and powerful visualization package that was originally designed to emulate the Matlab plotting paradigm. It has since evolved and as become a bit more user-friendly. It is still quite granular and can facilitate a lot of custom plots once you become familiar with it. However, as a starting point, I think it’s a bit much. We’ll see a bit of what it can offer later.
We will consider two other options which are built on top of matplotlib, but are much more accessible. These are pandas and seaborn. The two packages have some different approaches, but both wrap matplotlib in higher-level code and decent choices so we don’t need to get into the matplotlib trenches quite so much. We’ll still call matplotlib in our code, since both these packages need it for some fine tuning. Both packages are also very much aligned to the DataFrame construct in pandas, so makes plotting a much more seamless experience.
mtcars.plot.scatter(x = 'hp', y = 'mpg');
plt.show()
# mtcars.plot(x = 'hp', y = 'mpg', kind = 'scatter');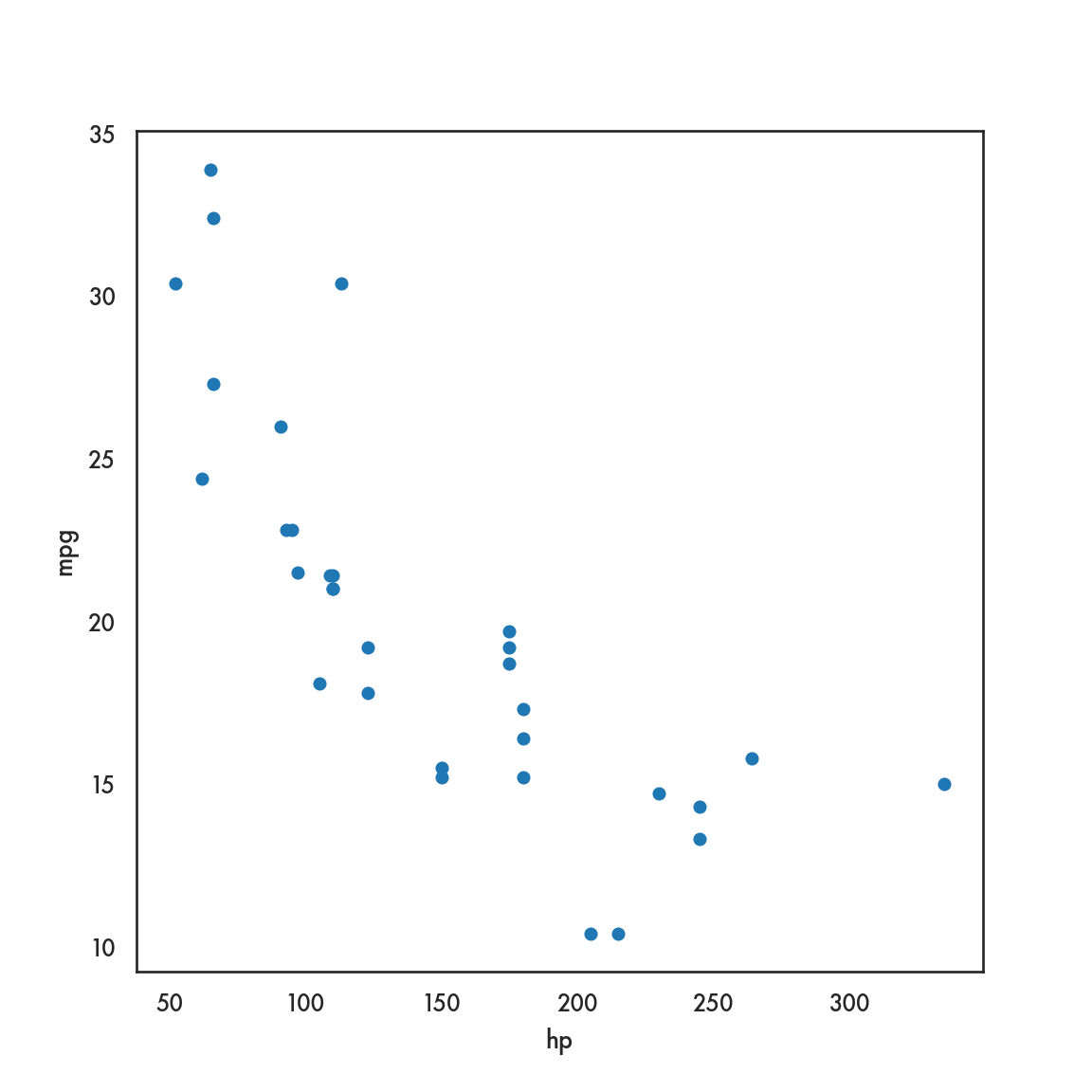
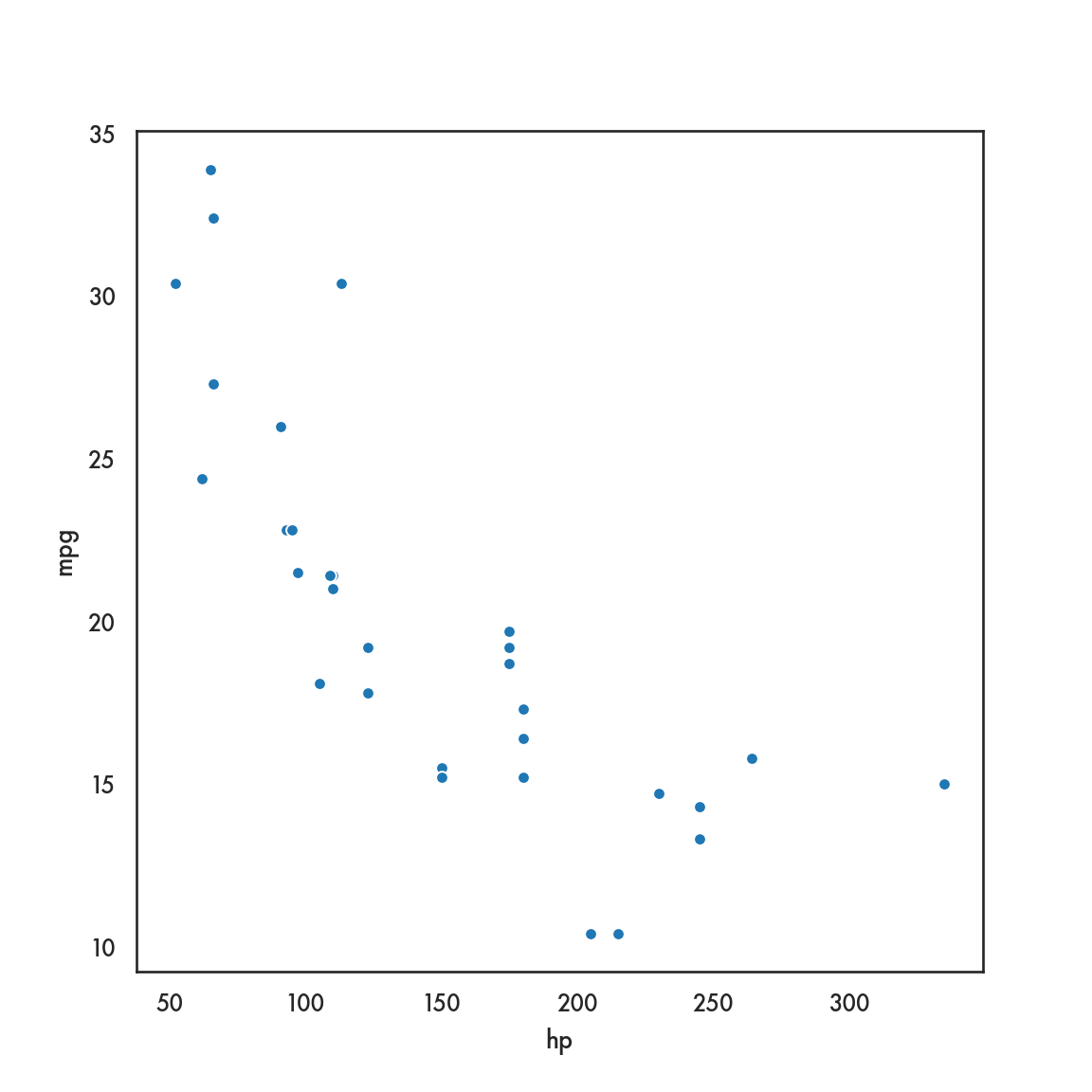
There are of course some other choices based on your background and preferences. For static plots, there are a couple of emulators of the popular R package ggplot2. These are plotnine and ggplot. plotnine seems a bit more developed and uses the ggplot2 semantics of aesthetics and layers, with almost identical code syntax.
You can install
plotnineusingconda:conda install -c conda-forge plotnine
<ggplot: (302395799)>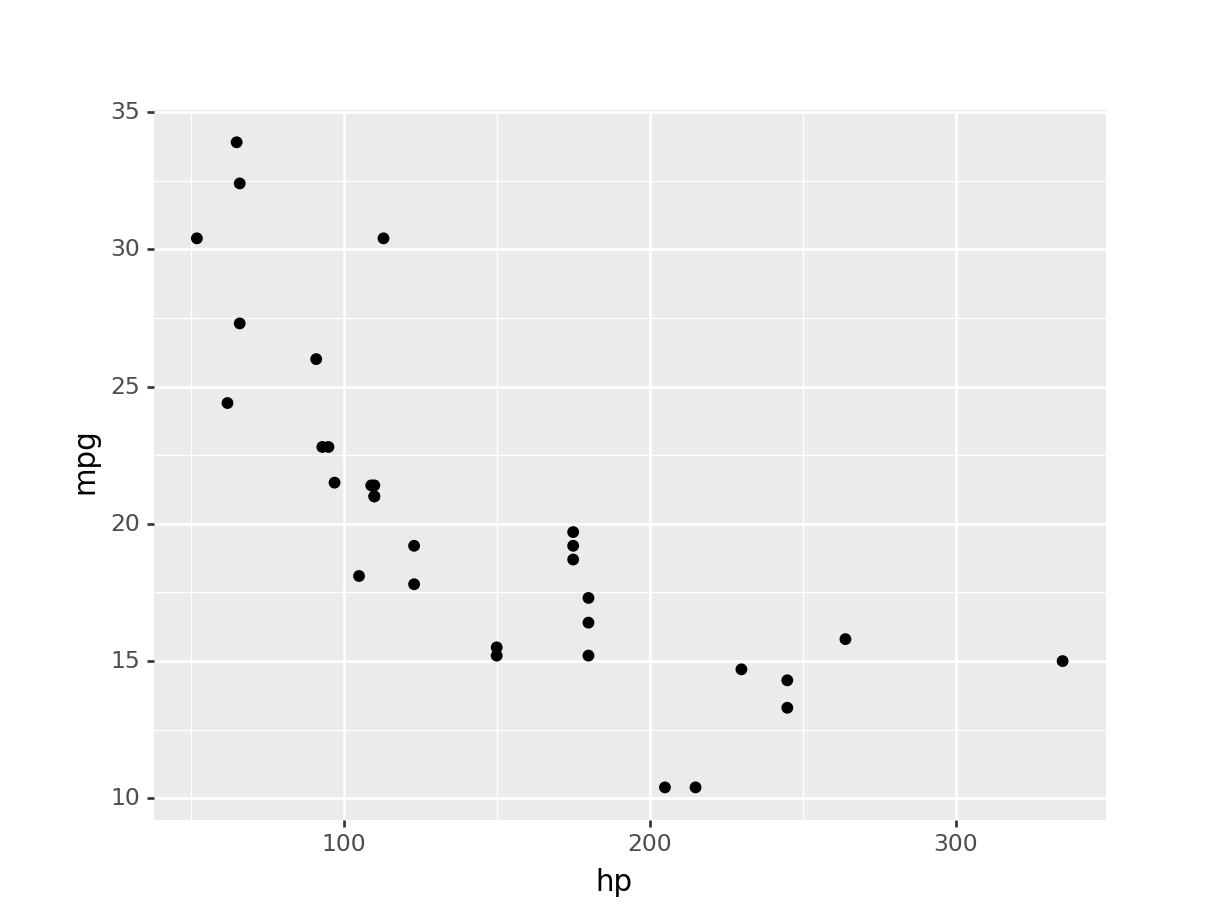
5.2.2 Dynamic or interactive plots
There are several Python packages that wrap around Javascript plotting libraries that are so popular in web-based graphics like D3 and Vega. Three that deserve mention are plotly, bokeh, and altair.
If you actually want to experience the interactivity of the plots, please use the “Live notebooks” link in Canvas to run these notebooks. Otherwise, you can download the notebooks from the GitHub site and run them on your own computer.
plotly is a Python package developed by the company Plot.ly to interface with their interactive Javascript library either locally or via their web service. Plot.ly also develops an R package to interface with their products as well. It provides an intuitive syntax and ease of use, and is probably the more popular package for interactive graphics from both R and Python.
bokeh is an interactive visualization package developed by Anaconda. It is quite powerful, but its code can be rather verbose and granular
from bokeh.plotting import figure, output_file
from bokeh.io import output_notebook, show
output_notebook()
p = figure()
p.xaxis.axis_label = 'Horsepower'
p.yaxis.axis_label = 'Miles per gallon'
p.circle(mtcars['hp'], mtcars['mpg'], size=10);
show(p)altair that leverages ideas from Javascript plotting libraries and a distinctive code syntax that may appeal to some
We won’t focus on these dynamic packages in this workshop in the interests of time, but you can avail of several online resources for these.
| Package | Resources |
|---|---|
| plotly | Fundamentals |
| bokeh | Tutorial |
| altair | Overview |
5.3 Univariate plots
We will be introducing plotting and code from 3 modules: matplotlib, seaborn and pandas. As we go forth, you may ask the question, which one should I learn? Chris Moffitt has the following advice.
A pathway to learning (Chris Moffit)
- Learn the basic matplotlib terminology, specifically what is a
Figureand anAxes. - Always use the object-oriented interface. Get in the habit of using it from the start of your analysis. (not really getting into this, but basically don’t use the Matlab form I’ll show at the end, if you don’t have to)
- Start your visualizations with basic pandas plotting.
- Use seaborn for the more complex statistical visualizations.
- Use matplotlib to customize the pandas or seaborn visualization.
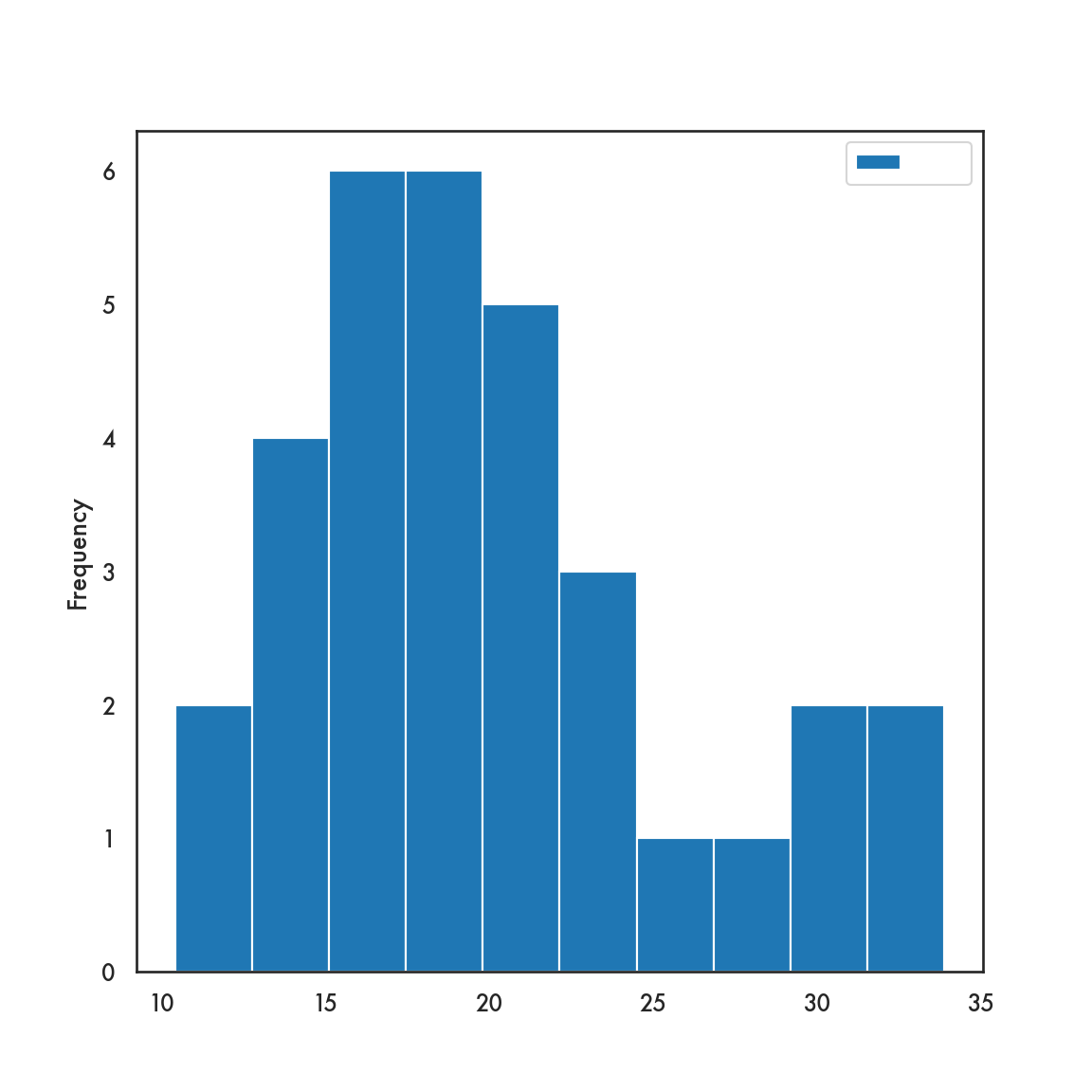
5.3.1 pandas
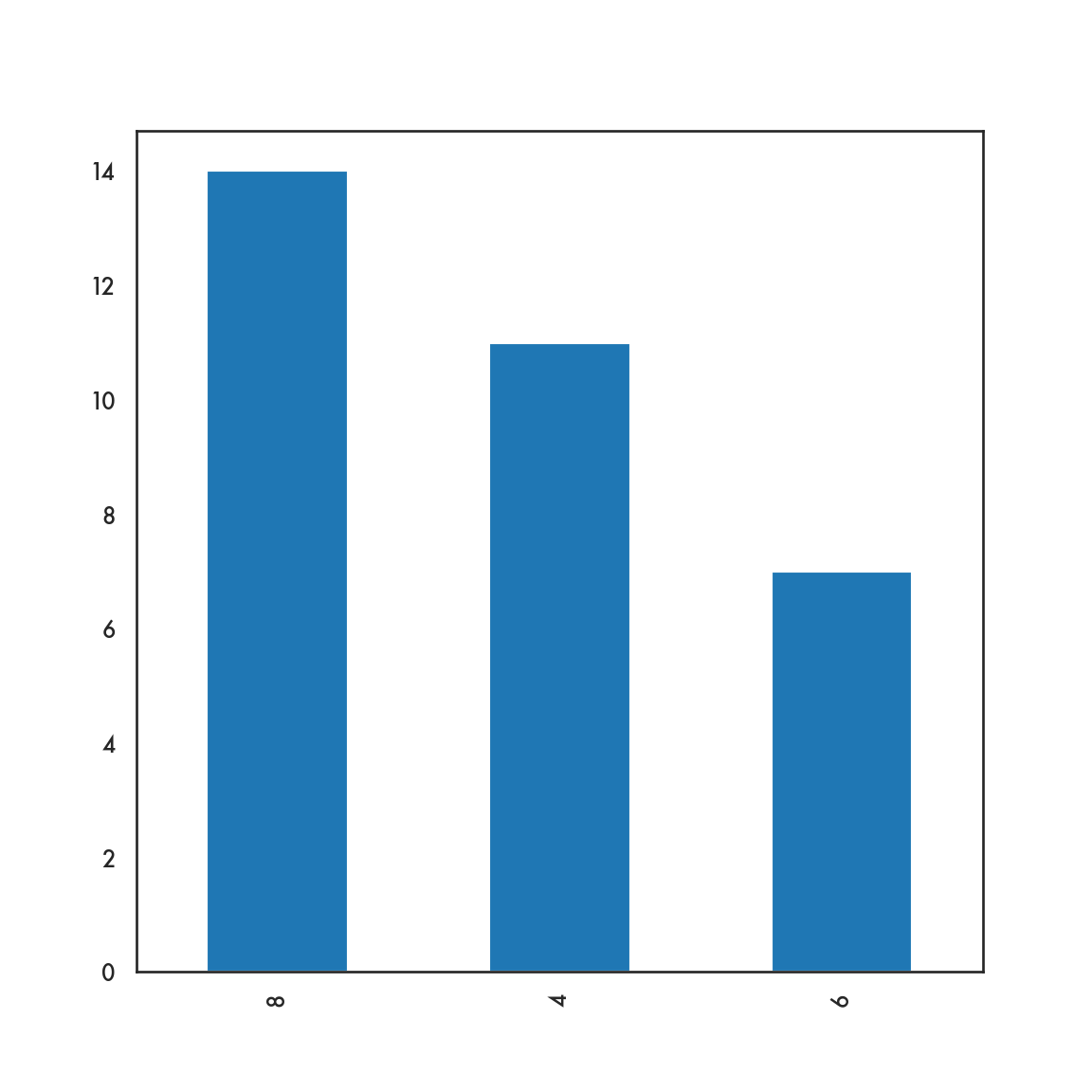
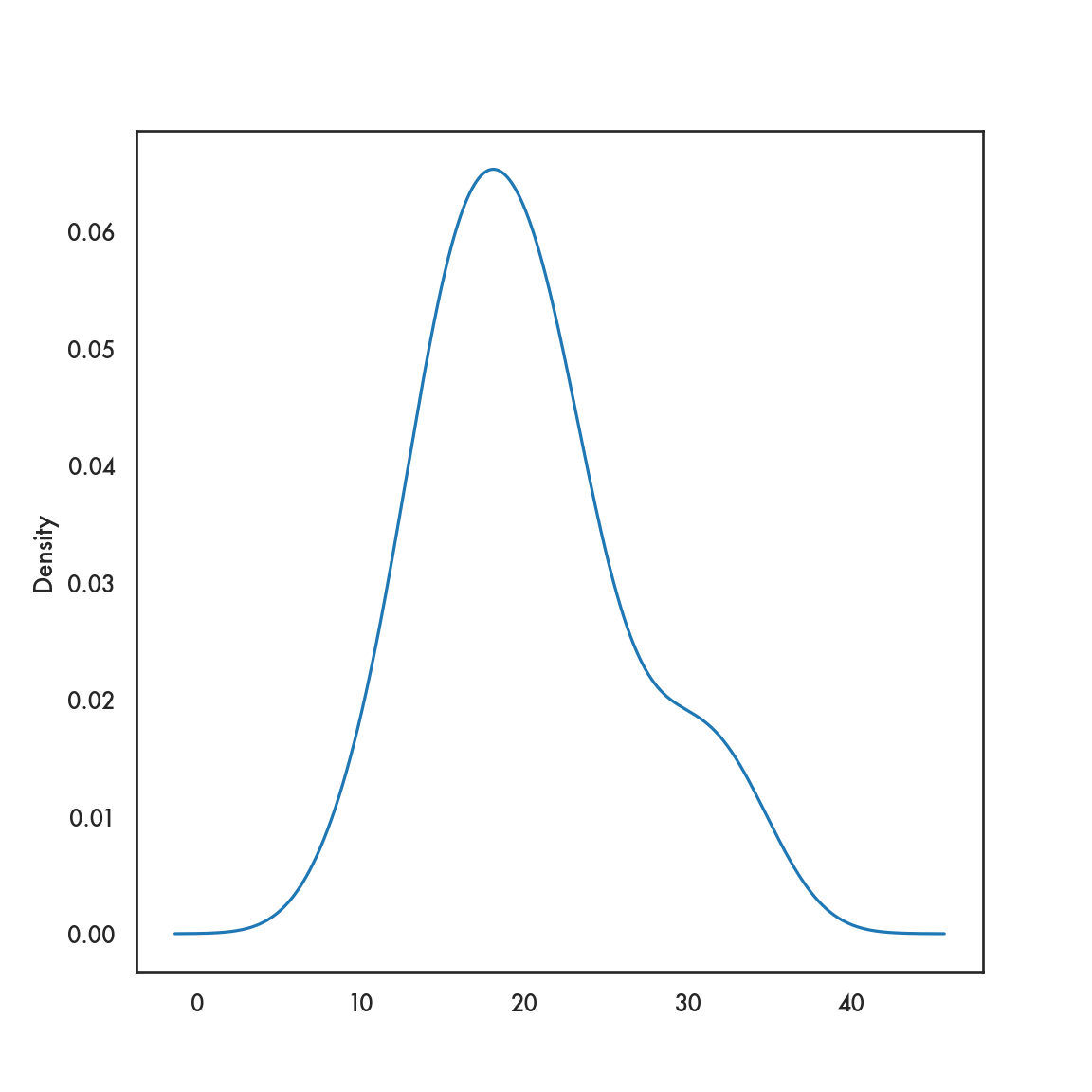
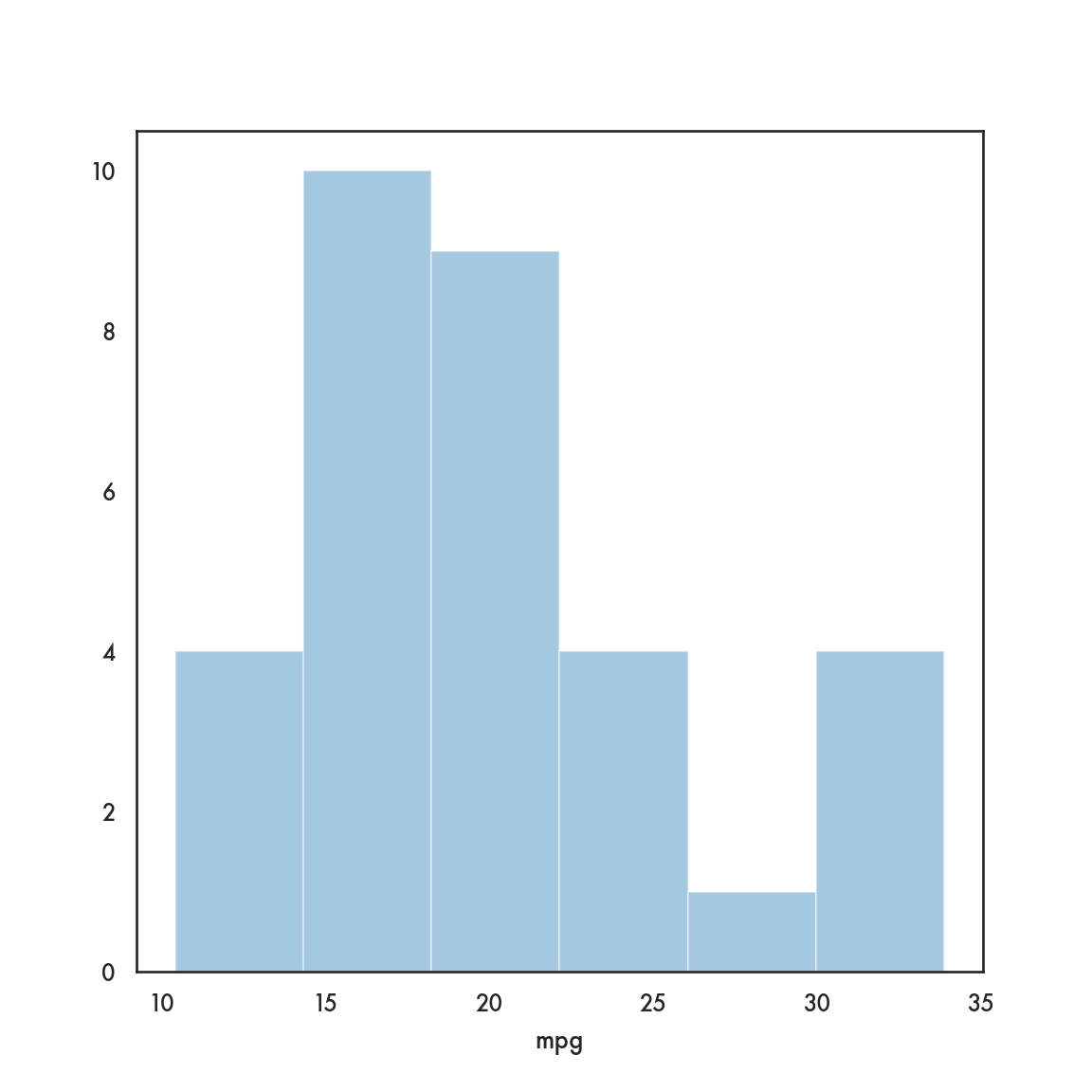
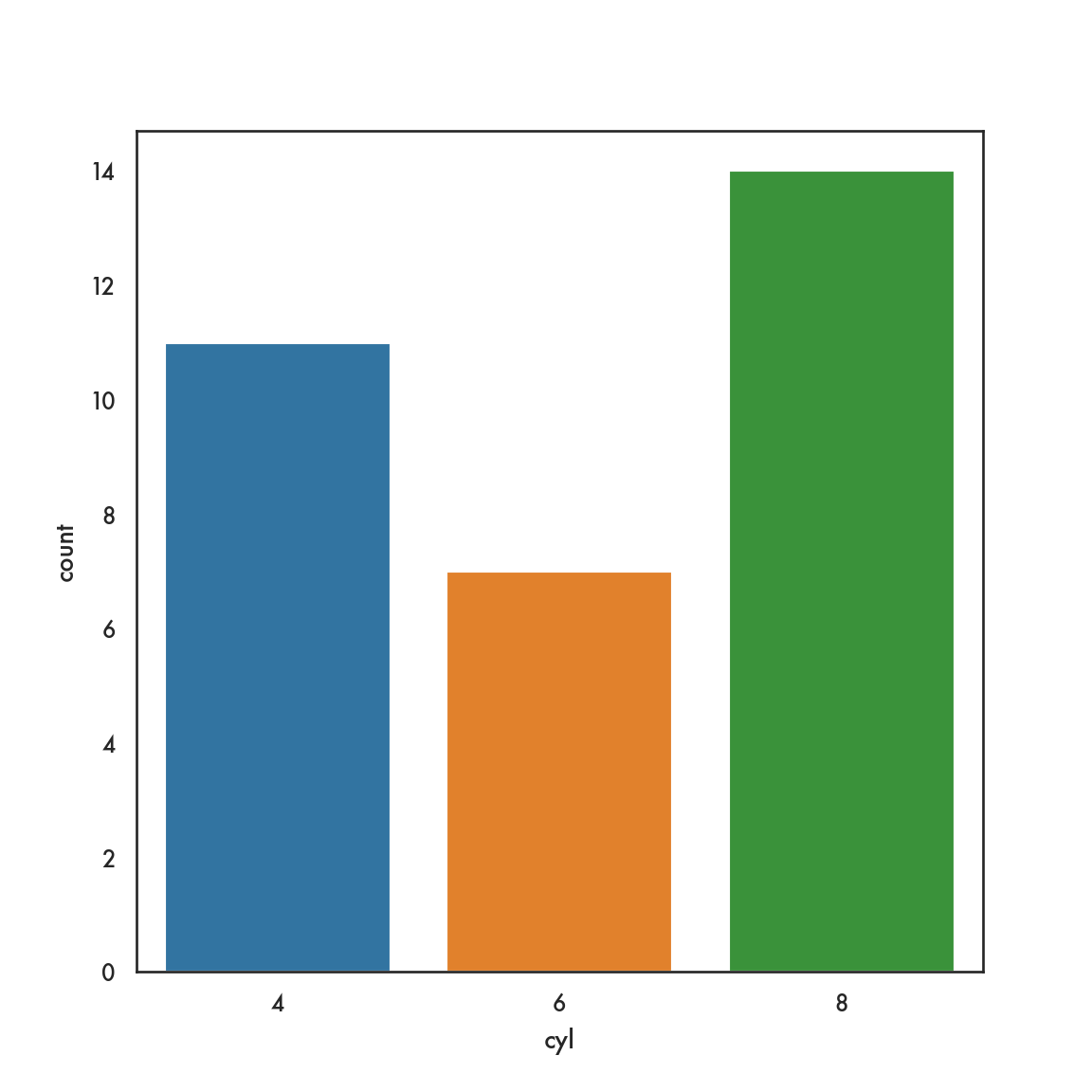
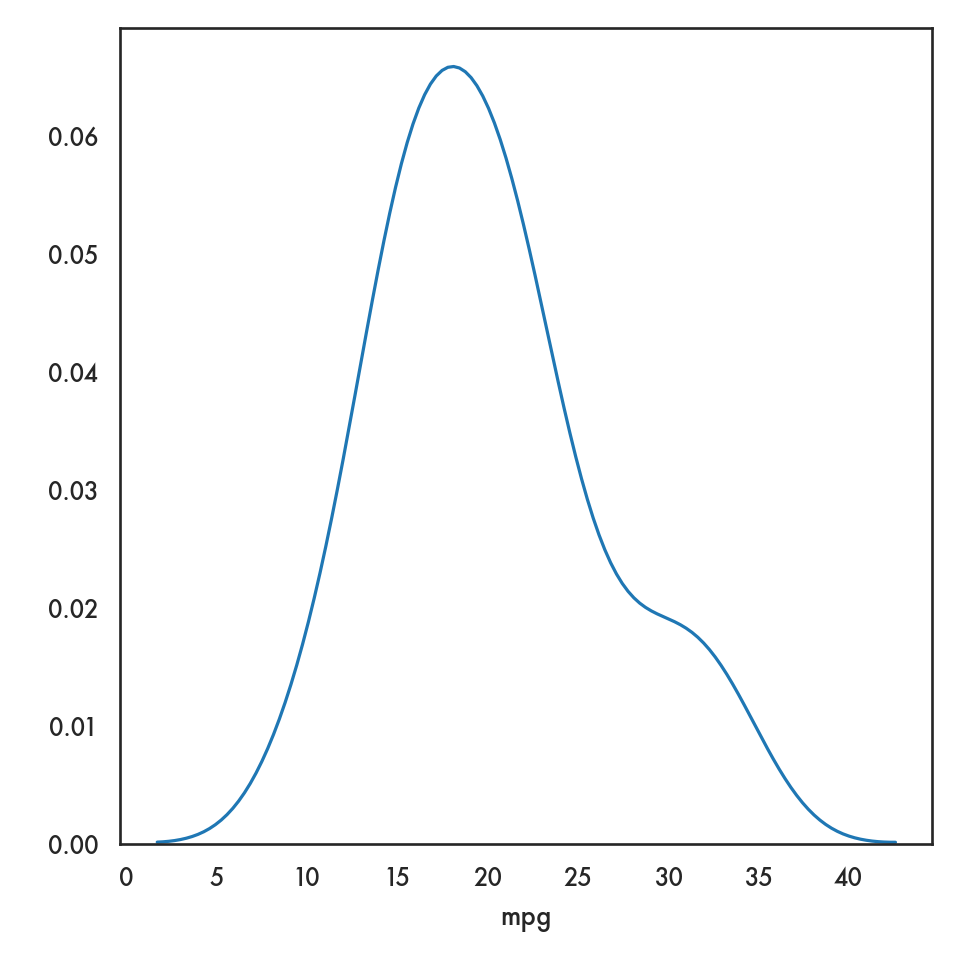
5.4 Bivariate plots
5.4.1 pandas
5.4.2 seaborn
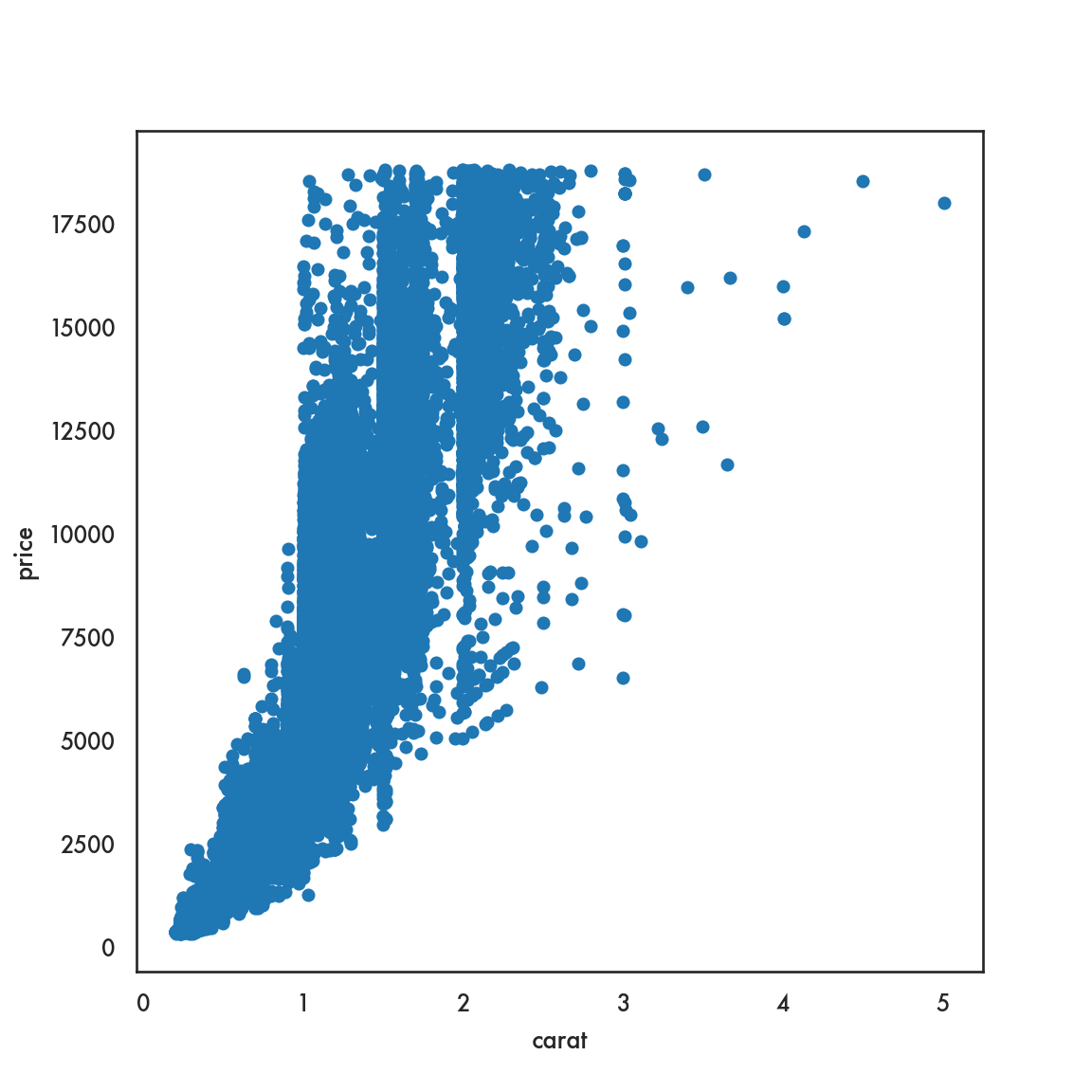
5.4.2.1 Scatter plot
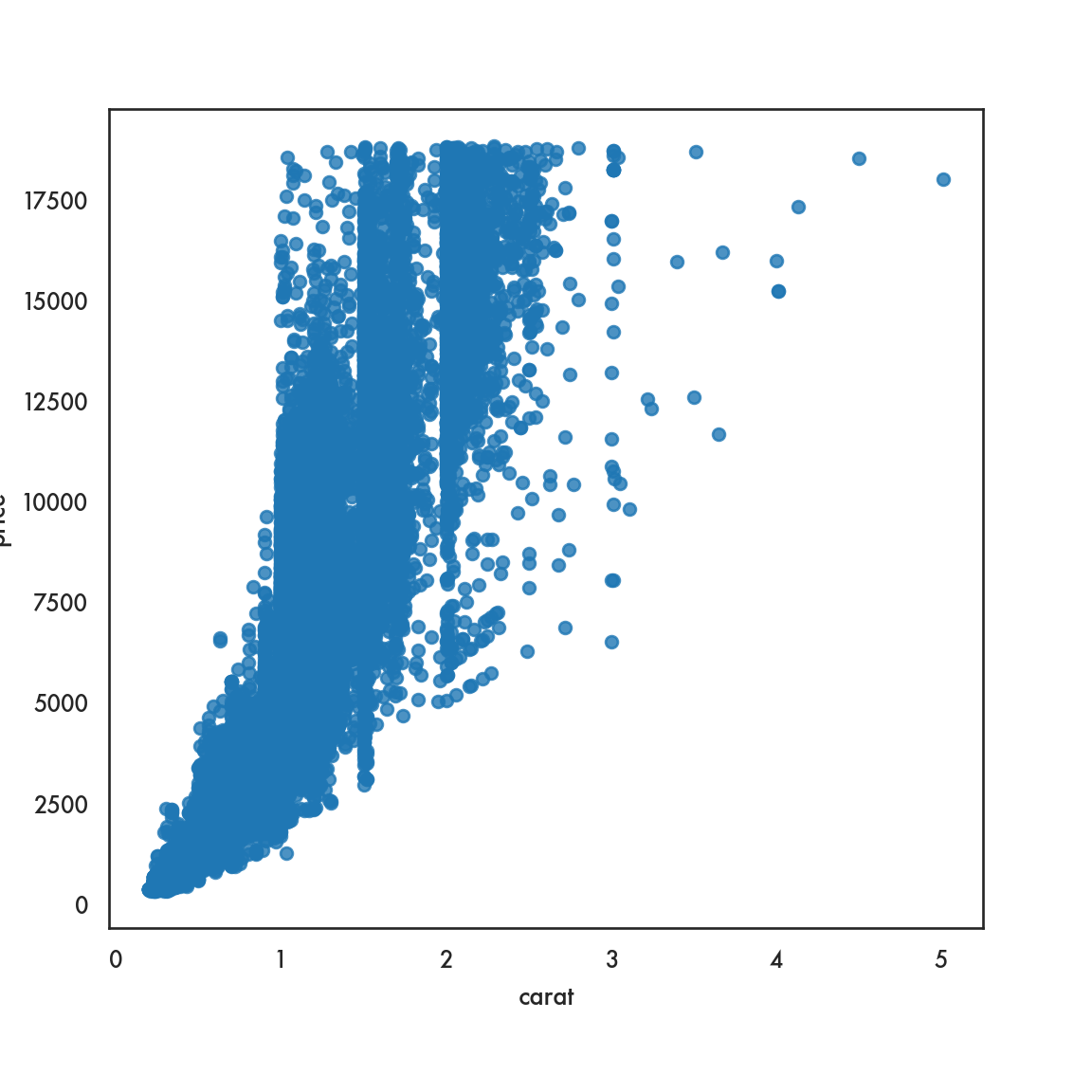
sns.scatterplot(data=diamonds, x = 'carat', y = 'price', linewidth=0);
# We set the linewidth to 0, otherwise the lines around the circles
# appear white and wash out the figure. Try with any positive
# value of linewidth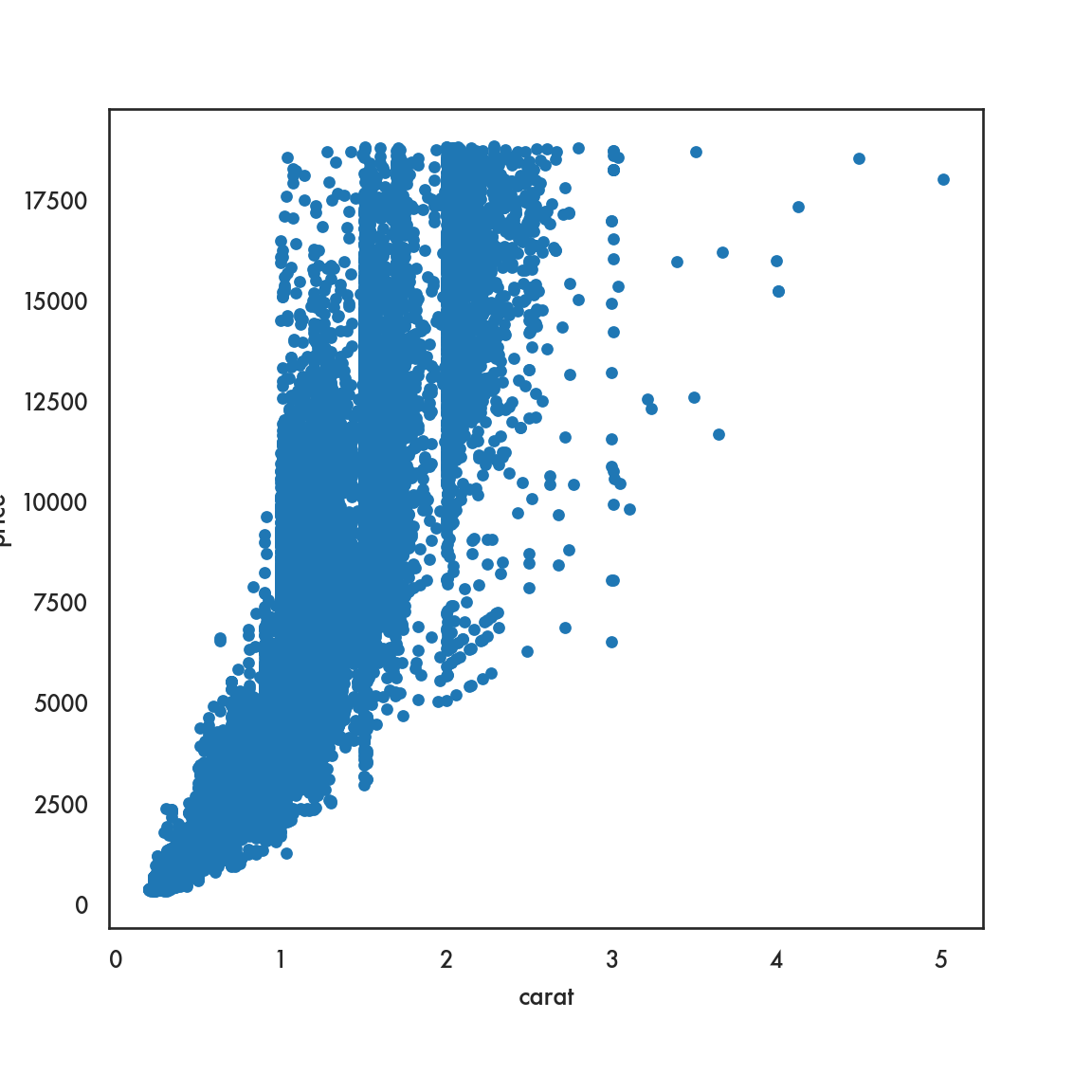
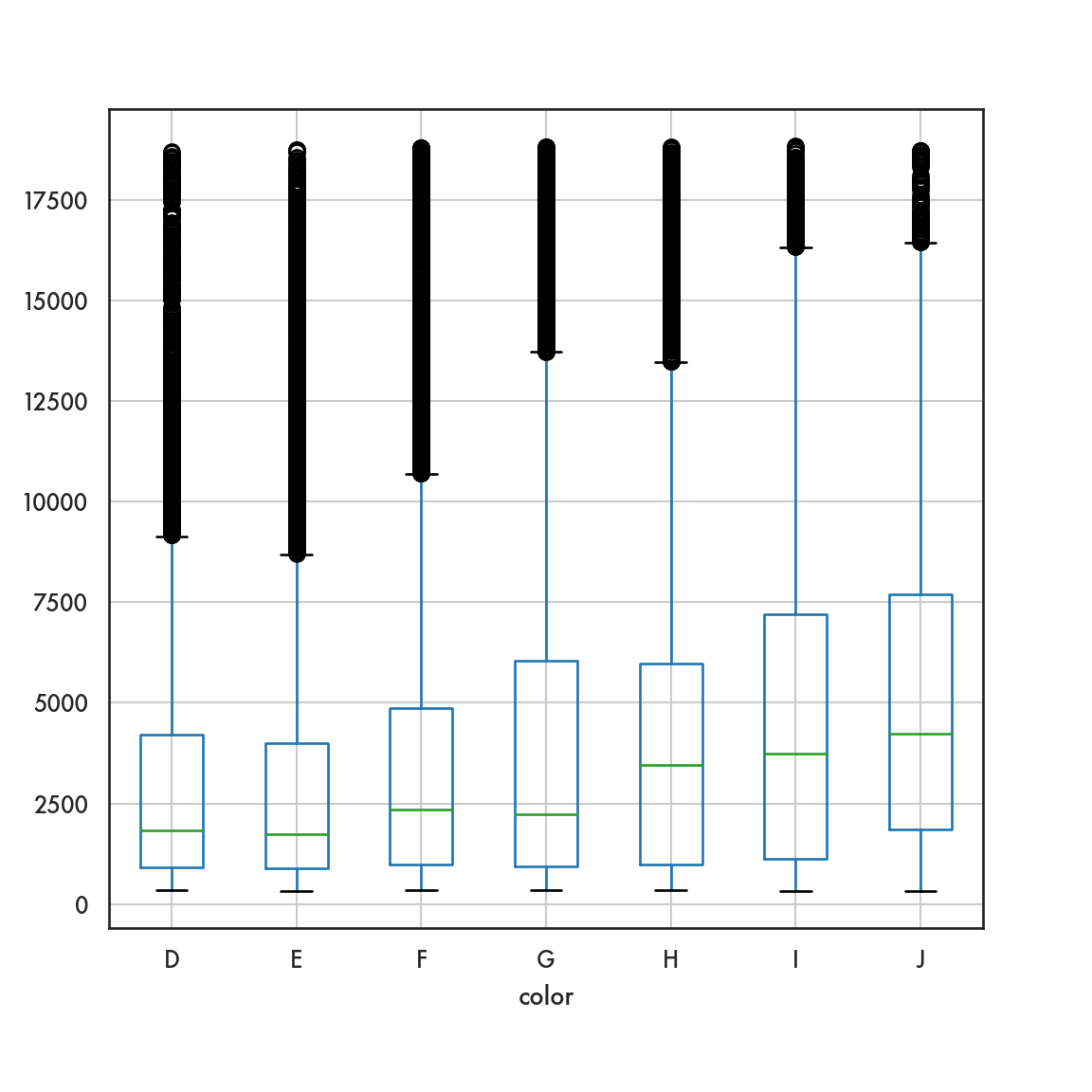
5.4.2.2 Box plot
ordered_color = ['E','F','G','H','I','J']
sns.catplot(data = diamonds, x = 'color', y = 'price',
order = ordered_color, color = 'blue', kind = 'box');
plt.show()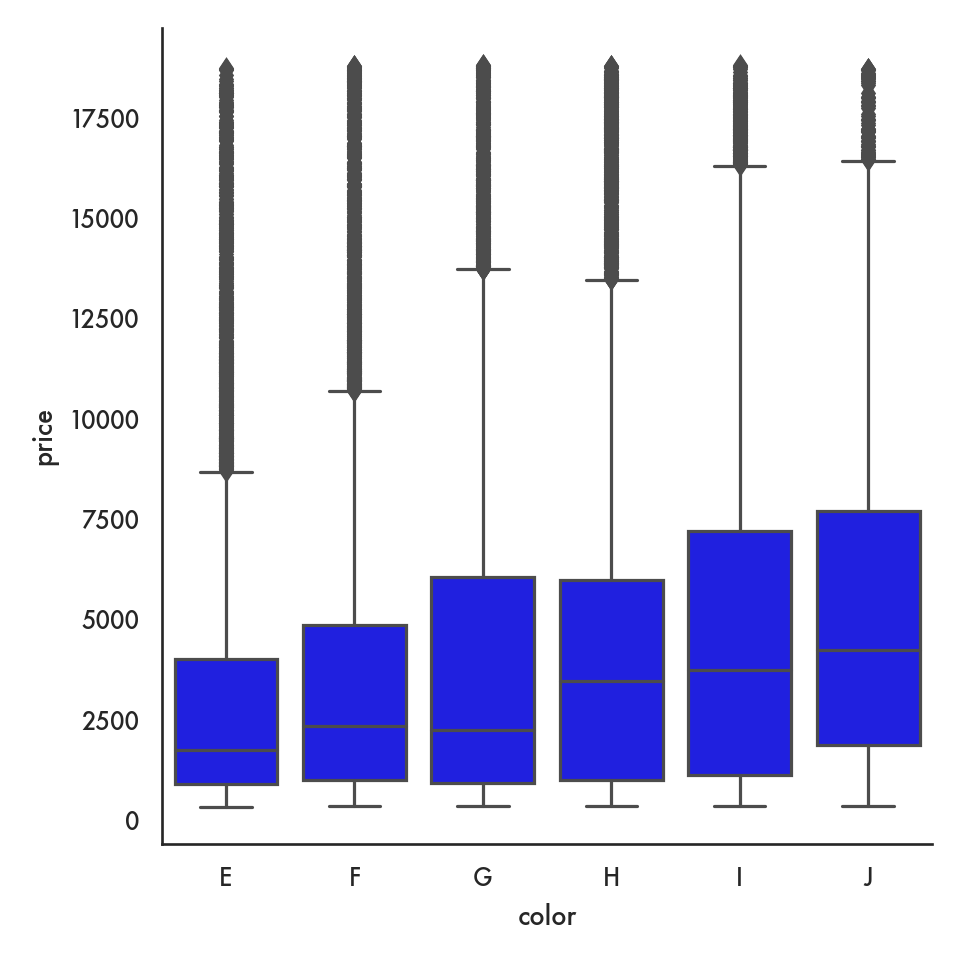
5.4.2.3 Violin plot
g = sns.catplot(data = diamonds, x = 'color', y = 'price',
kind = 'violin', order = ordered_color);
plt.show()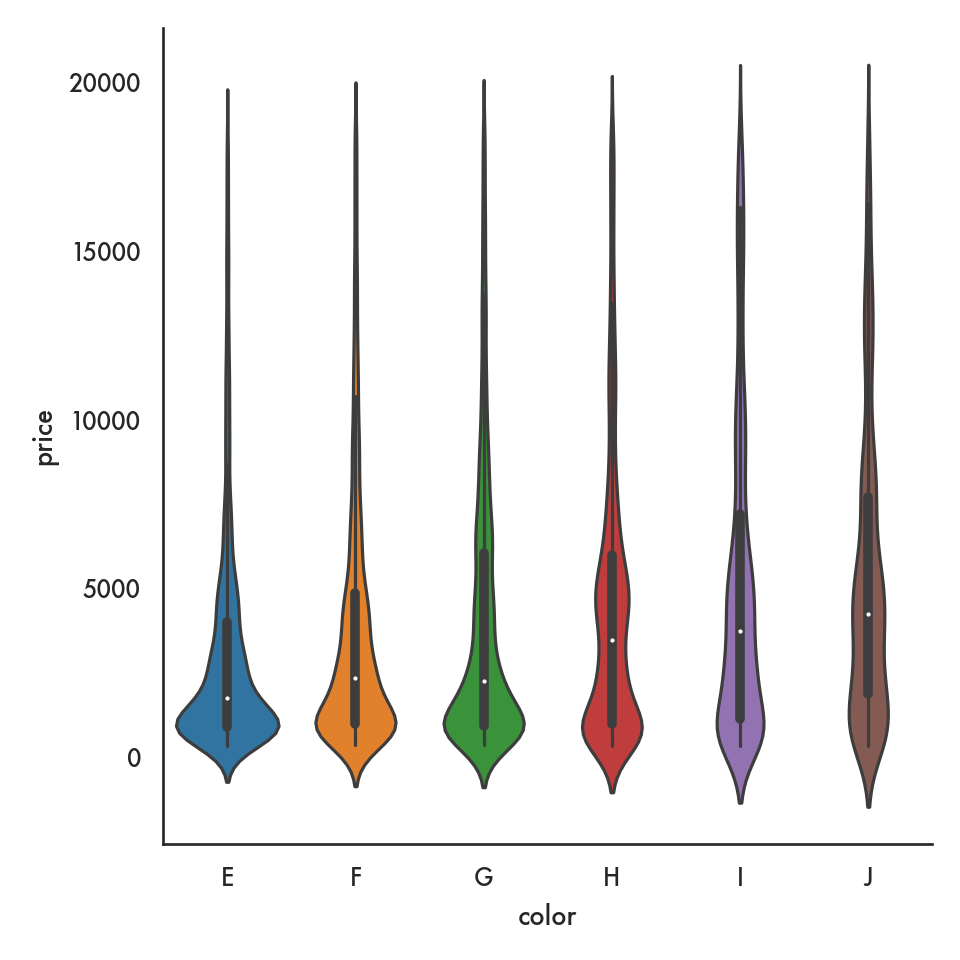
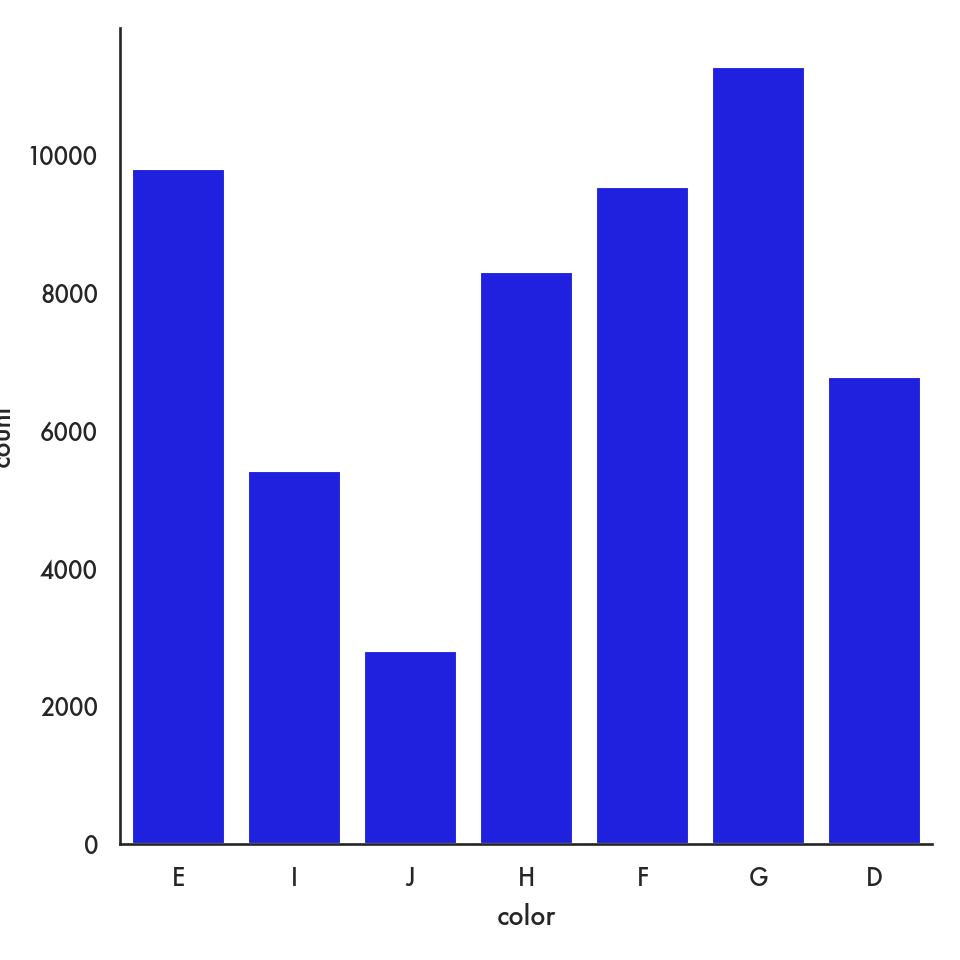
5.4.2.4 Barplot (categorical vs continuous)
ordered_colors = ['D','E','F','G','H','I']
sns.barplot(data = diamonds, x = 'color', y = 'price', order = ordered_colors);
plt.show()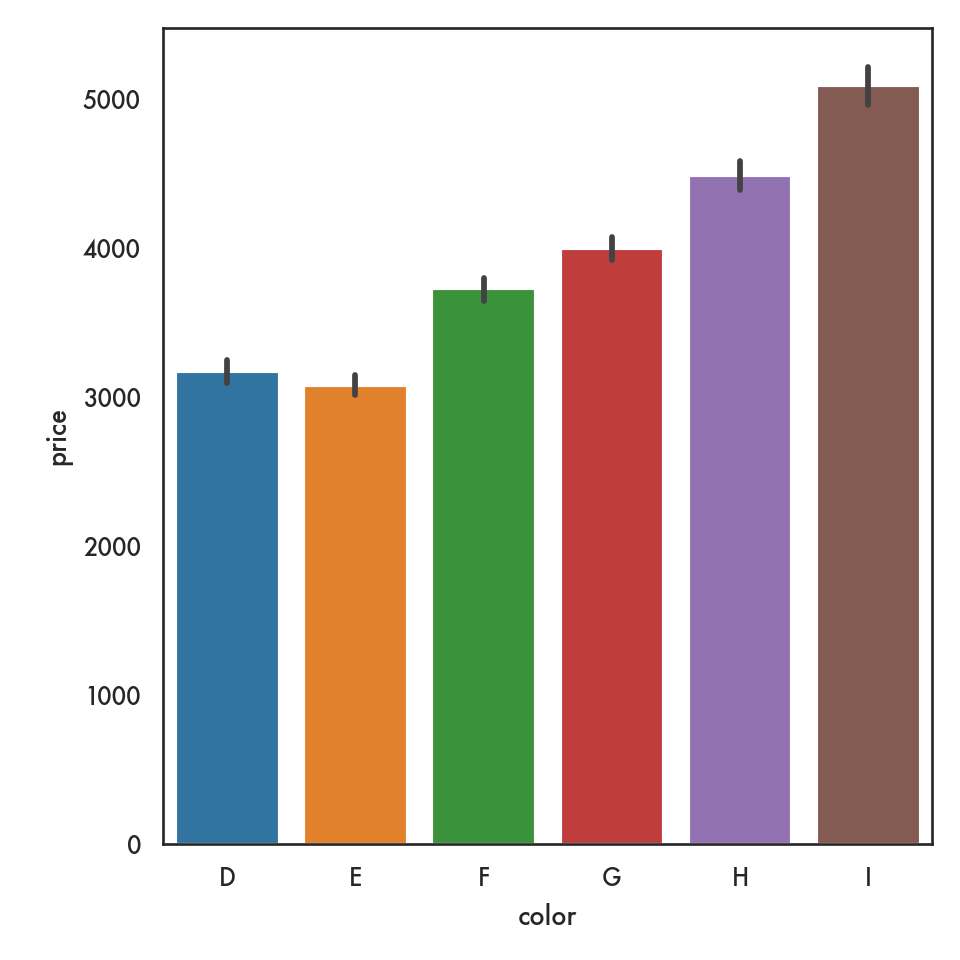
5.4.2.5 Joint plot
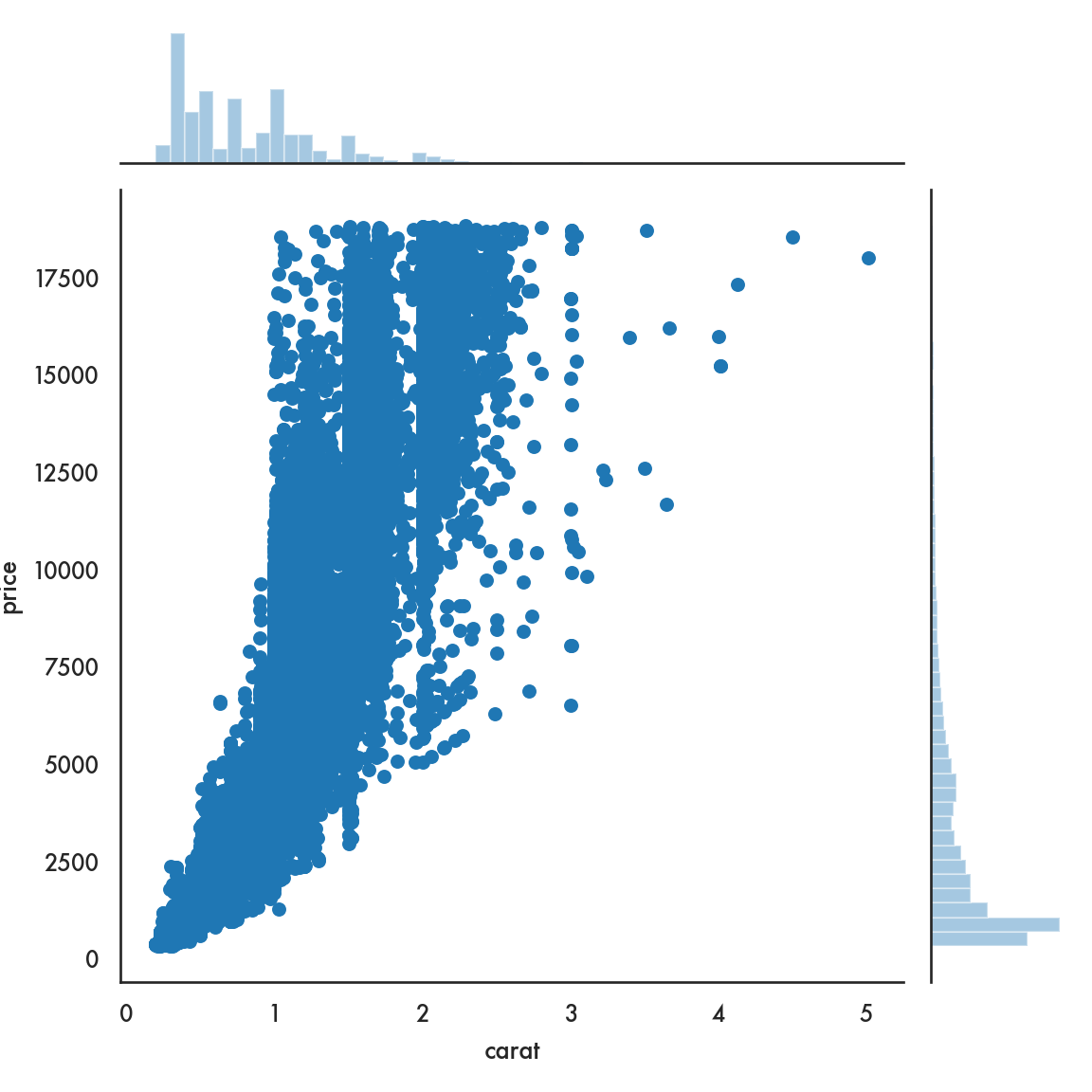
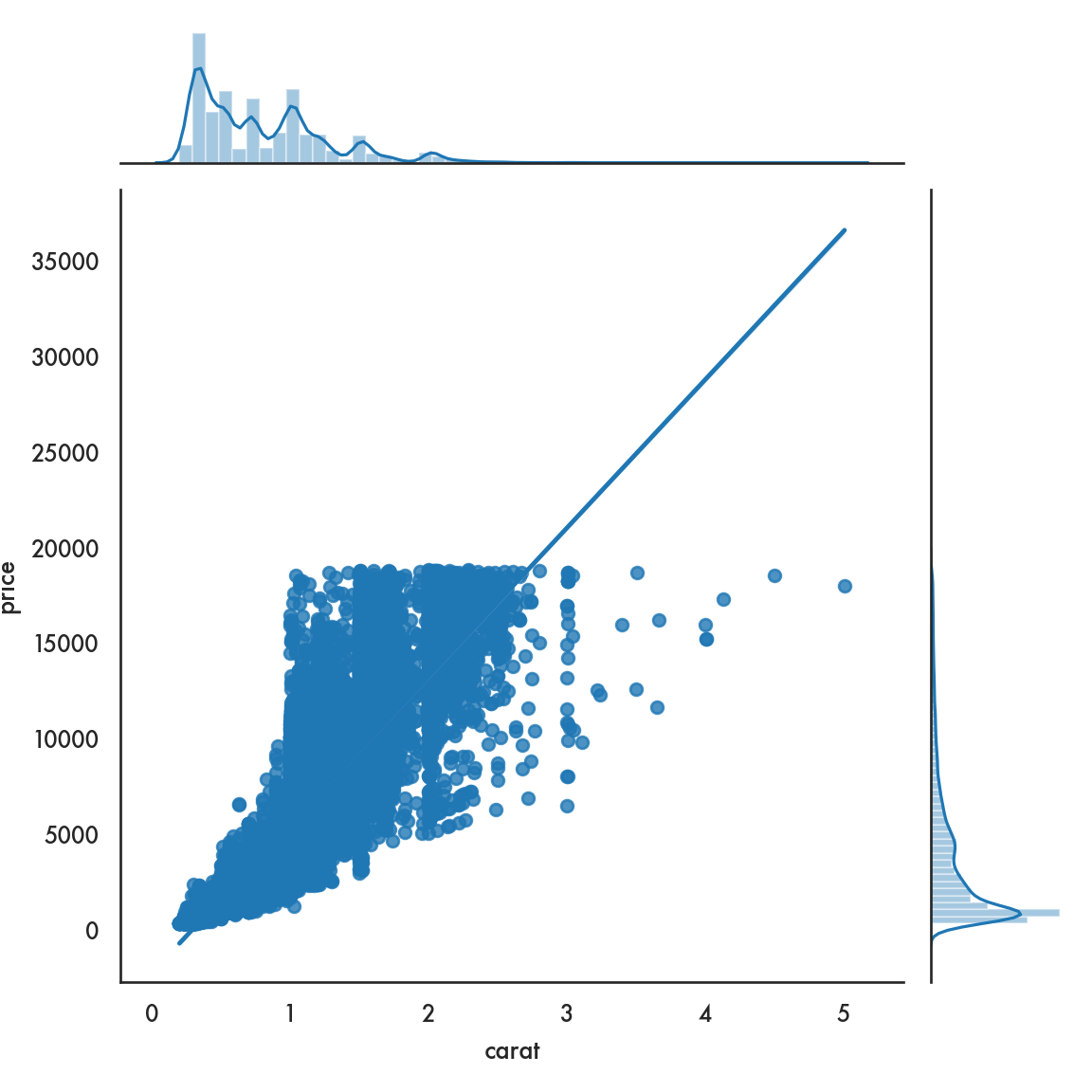
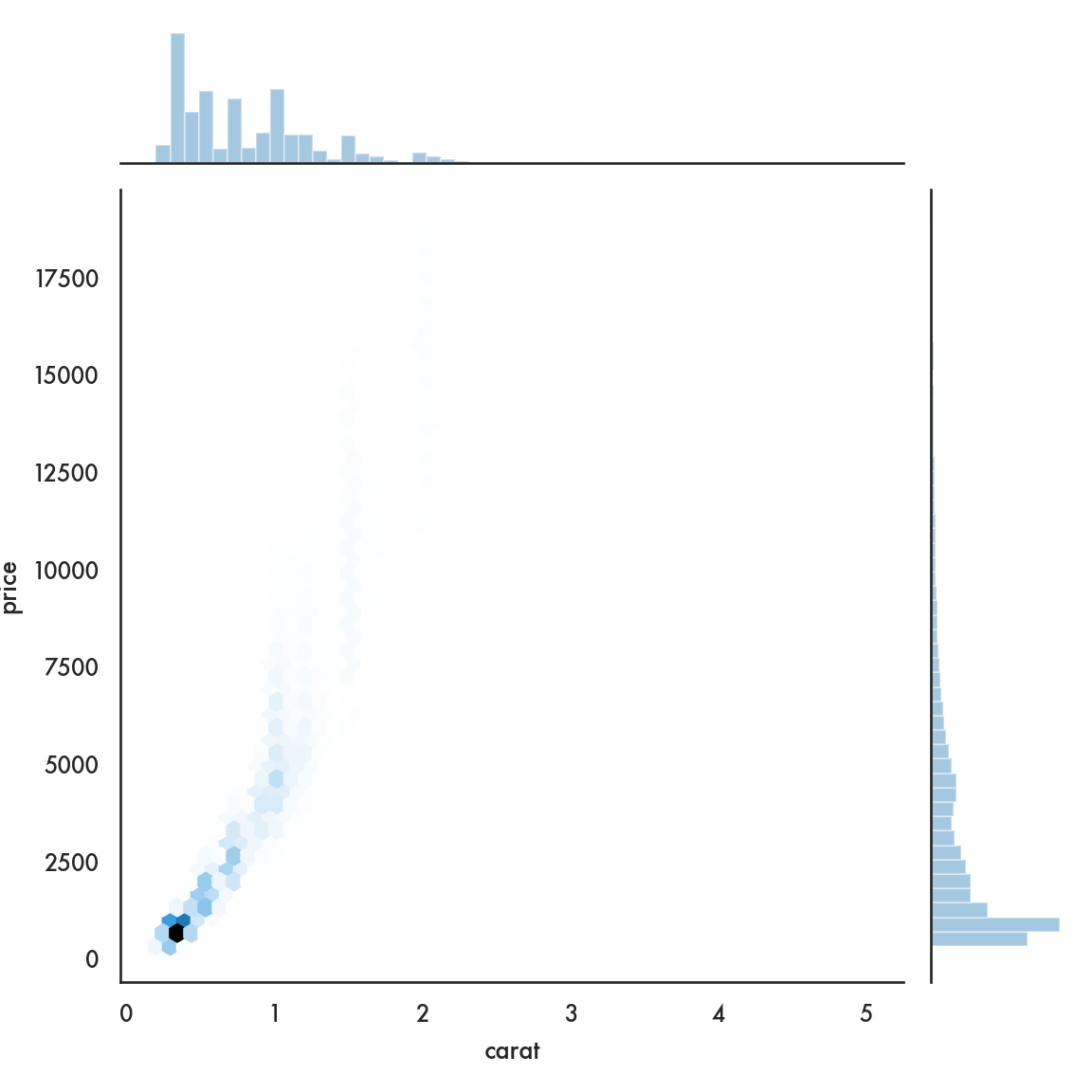 ## Facets and multivariate data
## Facets and multivariate data
The basic idea in this section is to see how we can visualize more than two variables at a time. We will see two strategies:
- Put multiple graphs on the same frame, with each graph referring to a level of a 3rd variable
- Create a grid of separate graphs, with each graph referring to a level of a 3rd variable
This strategy also can work any time we need to visualize the data corresponding to different levels of a variable, say by gender or race or country.
In this example we’re going to start with 4 time series, labelled A, B, C, D.
ts = pd.read_csv('data/ts.csv')
ts.dt = pd.to_datetime(ts.dt) # convert this column to a datetime object
ts.head() dt kind value
0 2000-01-01 A 1.442521
1 2000-01-02 A 1.981290
2 2000-01-03 A 1.586494
3 2000-01-04 A 1.378969
4 2000-01-05 A -0.277937For one strategy we will employ, it is actually a bit easier to change this to a wide data form, using pivot.
kind A B C D
dt
2000-01-01 1.442521 1.808741 0.437415 0.096980
2000-01-02 1.981290 2.277020 0.706127 -1.523108
2000-01-03 1.586494 3.474392 1.358063 -3.100735
2000-01-04 1.378969 2.906132 0.262223 -2.660599
2000-01-05 -0.277937 3.489553 0.796743 -3.417402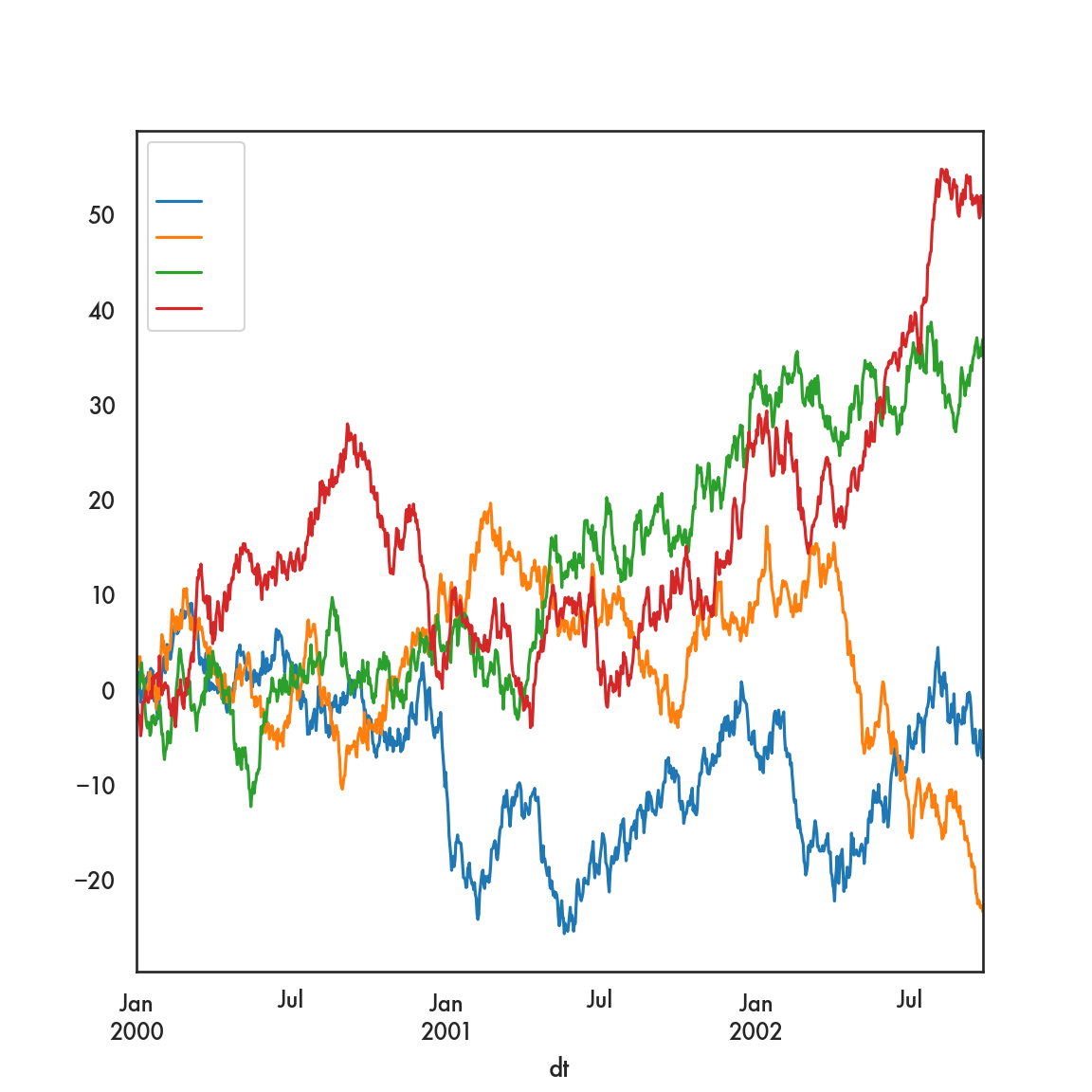
This creates 4 separate time series plots, one for each of the columns labeled A, B, C and D. The x-axis is determined by dfp.index, which during the pivoting operation, we deemed was the values of dt in the original data.
Using seaborn…
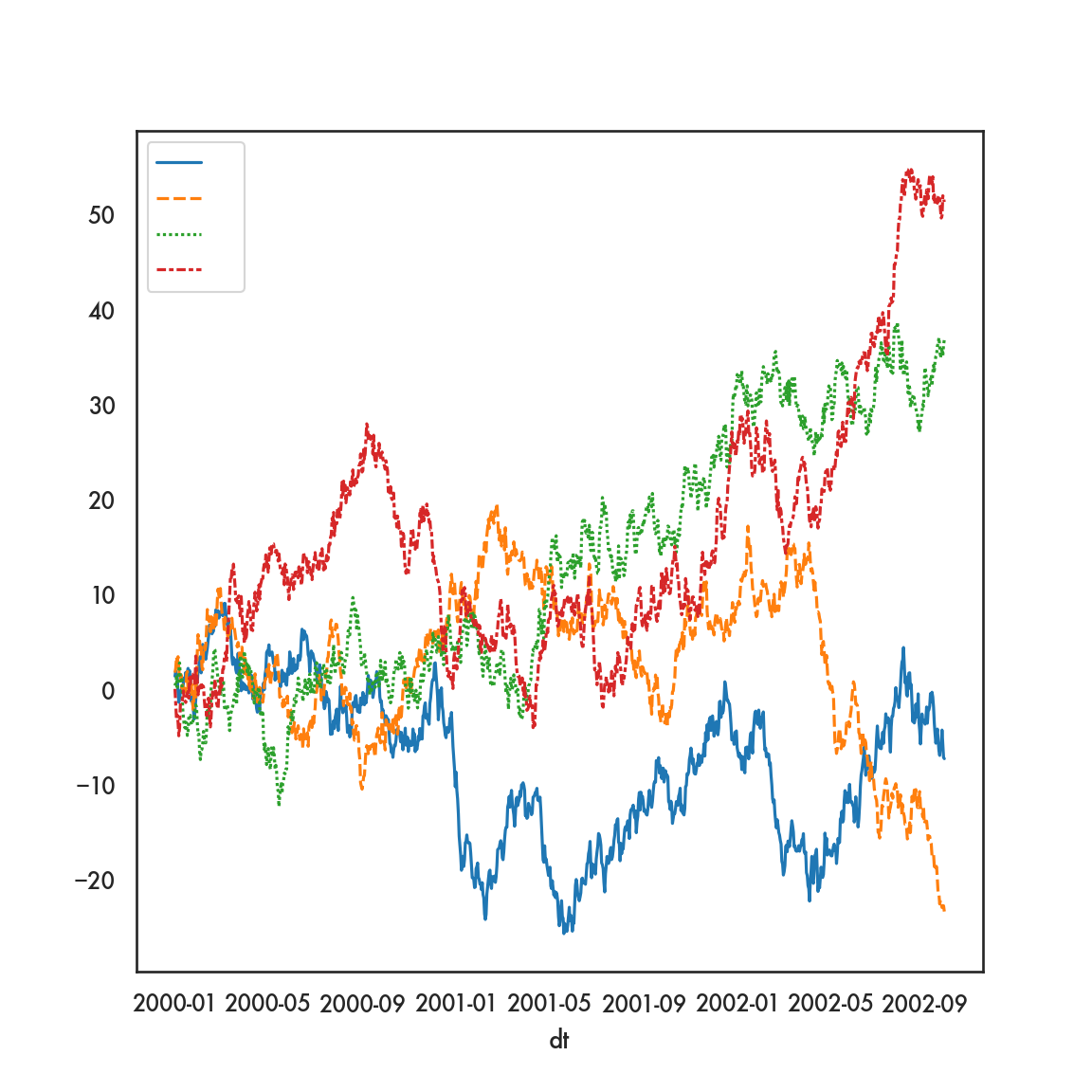
However, we can achieve this same plot using the original data, and seaborn, in rather short order
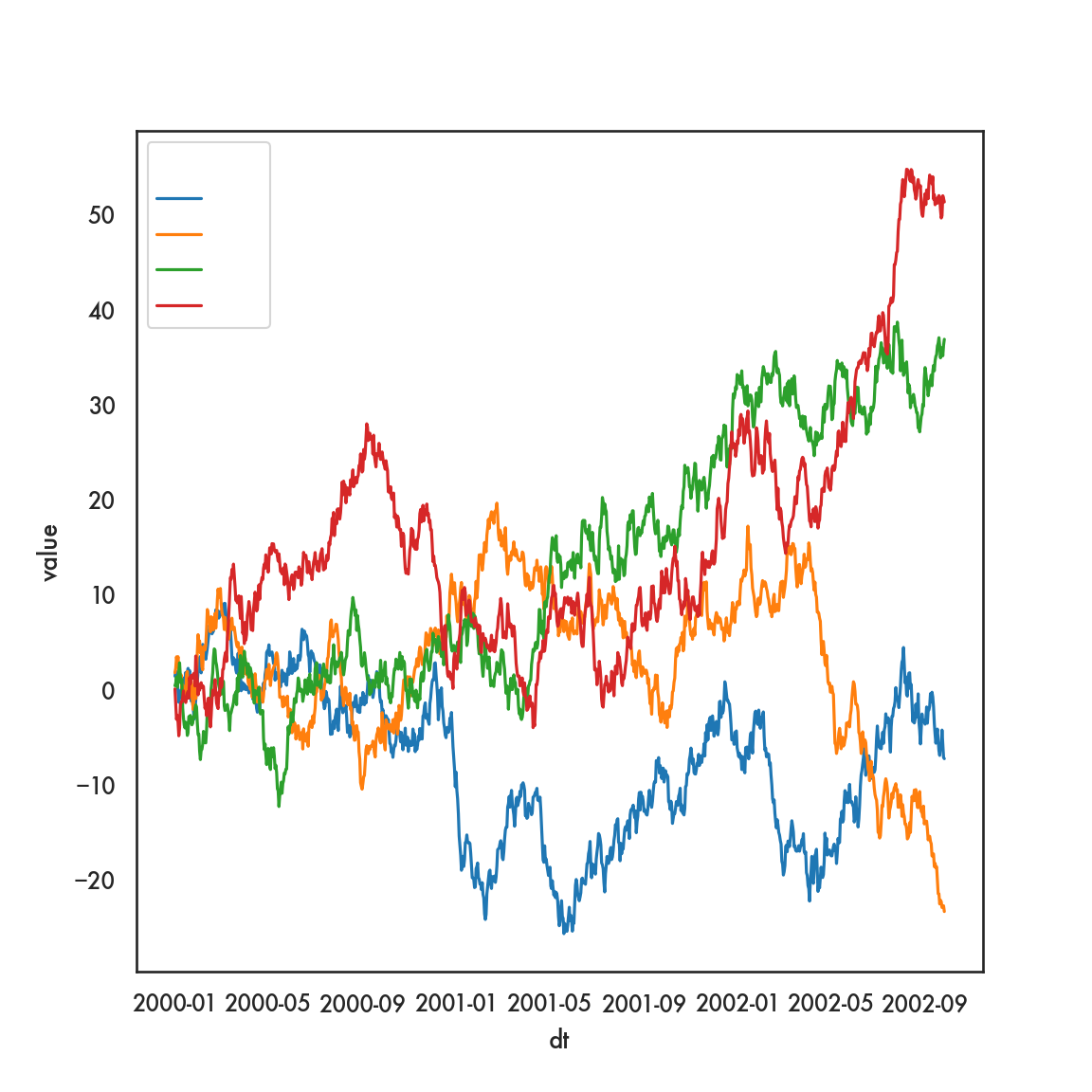
In this plot, assigning a variable to hue tells seaborn to draw lines (in this case) of different hues based on values of that variable.
We can use a bit more granular and explicit code for this as well. This allows us a bit more control of the plot.
g = sns.FacetGrid(ts, hue = 'kind', height = 5, aspect = 1.5)
g.map(plt.plot, 'dt', 'value').add_legend()<seaborn.axisgrid.FacetGrid object at 0x1319093d0>g.ax.set(xlabel = 'Date',
ylabel = 'Value',
title = 'Time series');
plt.show()
## All of this code chunk needs to be run at one time, otherwise you get weird errors. This
## is true for many plotting commands which are composed of multiple commands. 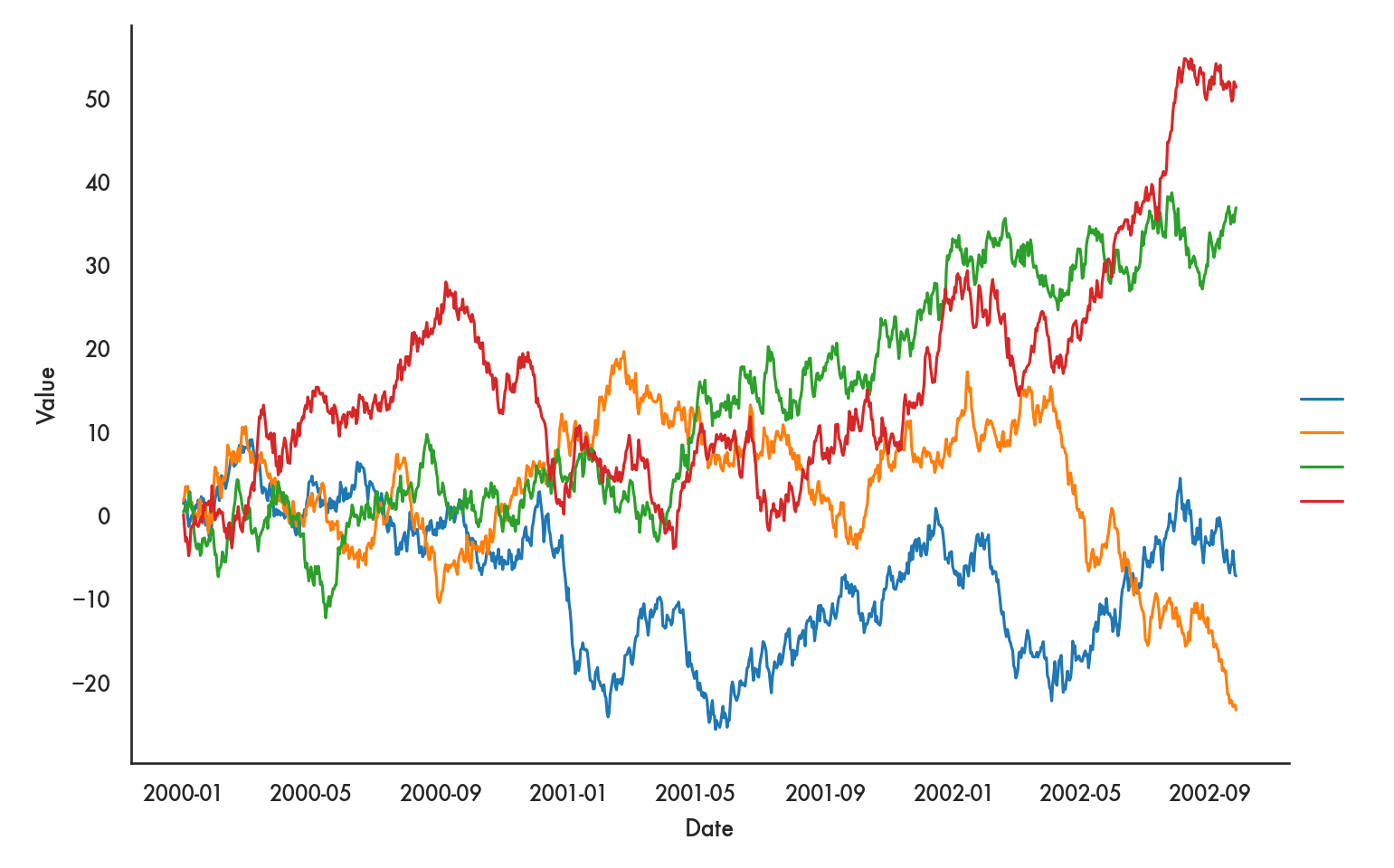
The FacetGrid tells seaborn that we’re going to layer graphs, with layers based on hue and the hues being determined by values of kind. Notice that we can add a few more details like the aspect ratio of the plot and so on. The documentation for FacetGrid, which we will also use for facets below, may be helpful in finding all the options you can control.
We can also show more than one kind of layer on a single graph
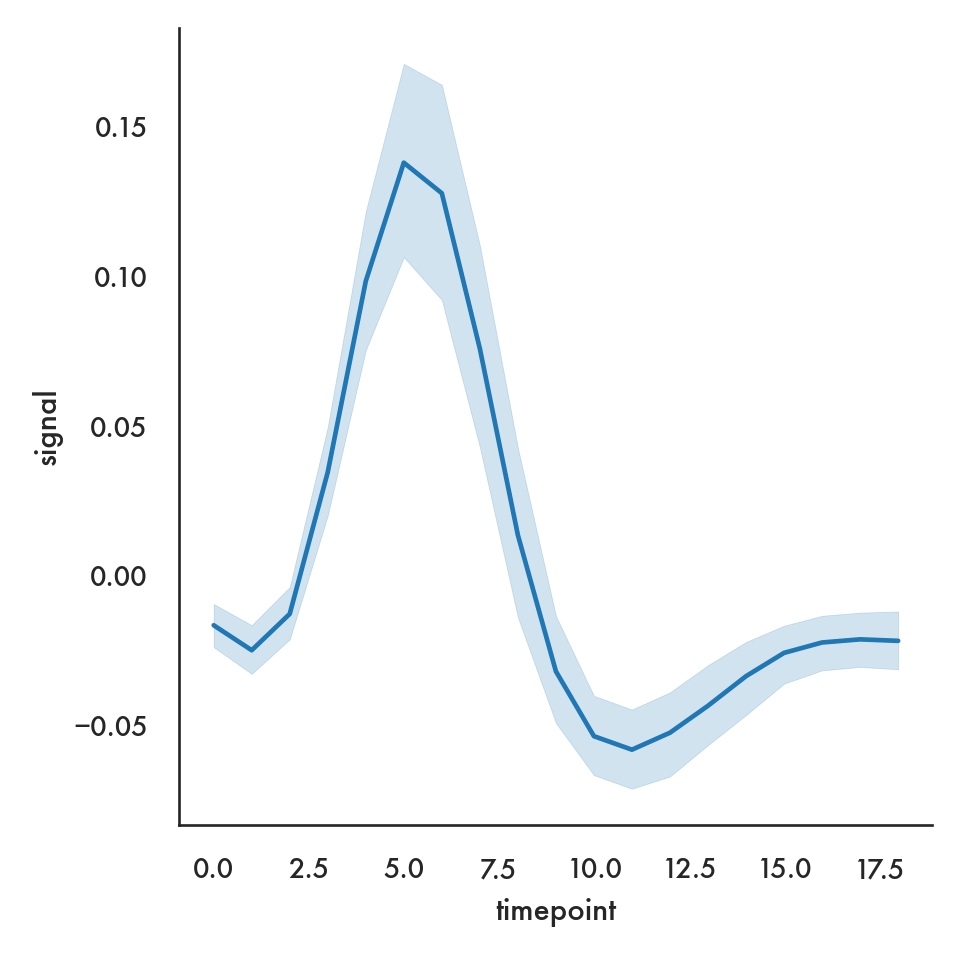
plt.style.use('seaborn-notebook')
sns.relplot(x = 'timepoint', y = 'signal', data = fmri);
plt.show()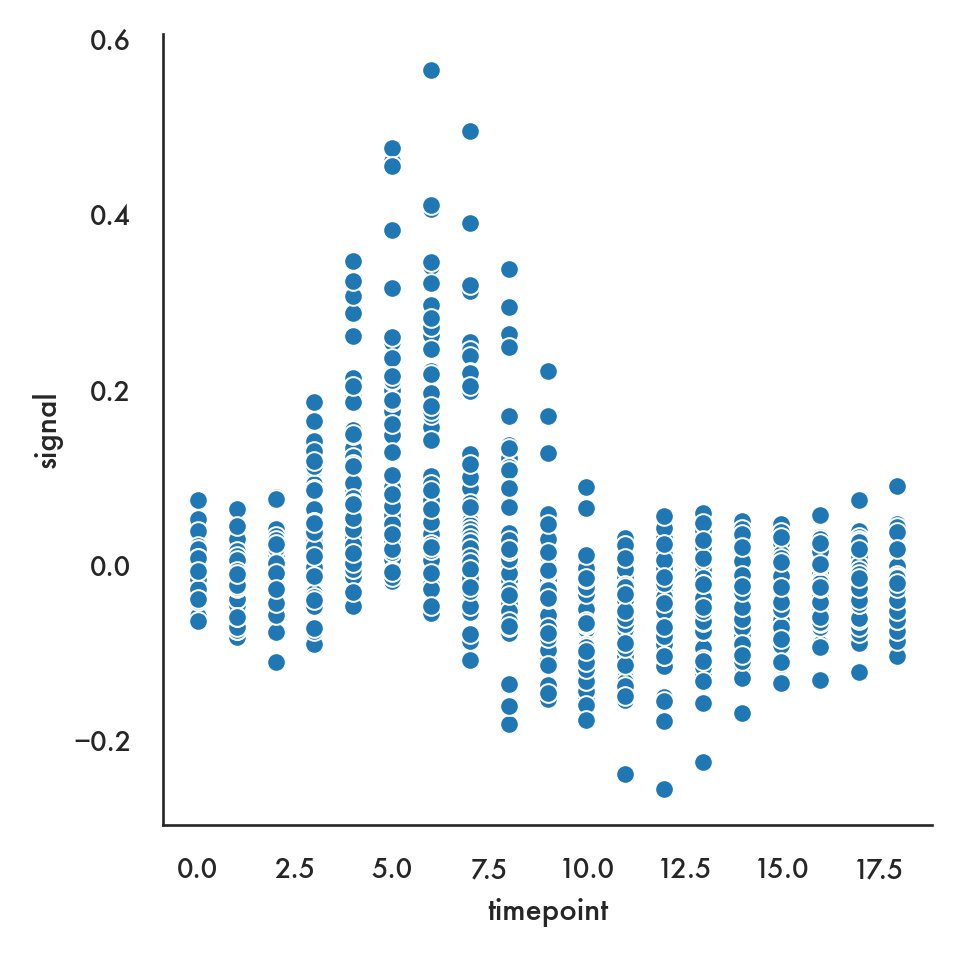
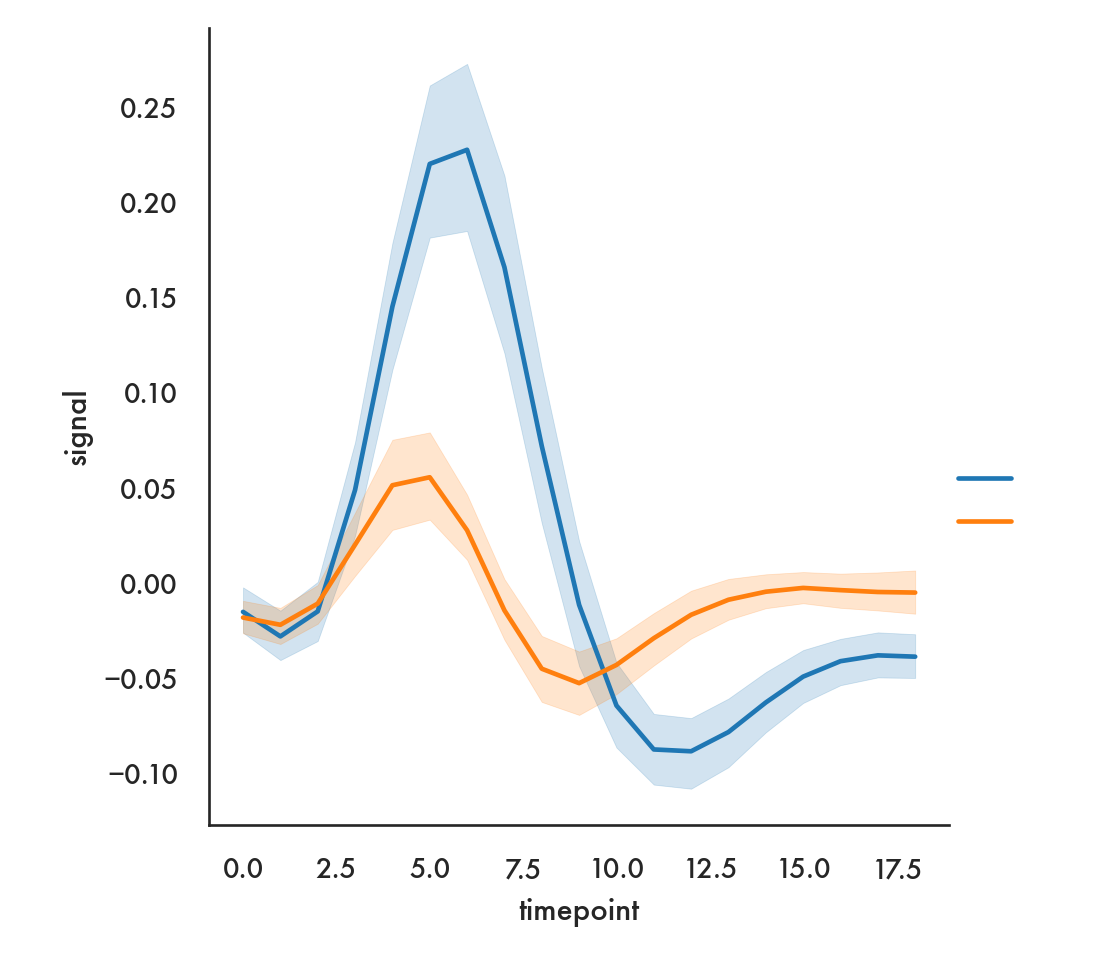
sns.relplot(x = 'timepoint', y = 'signal', data = fmri, hue = 'region',
style = 'event', kind = 'line');
plt.show()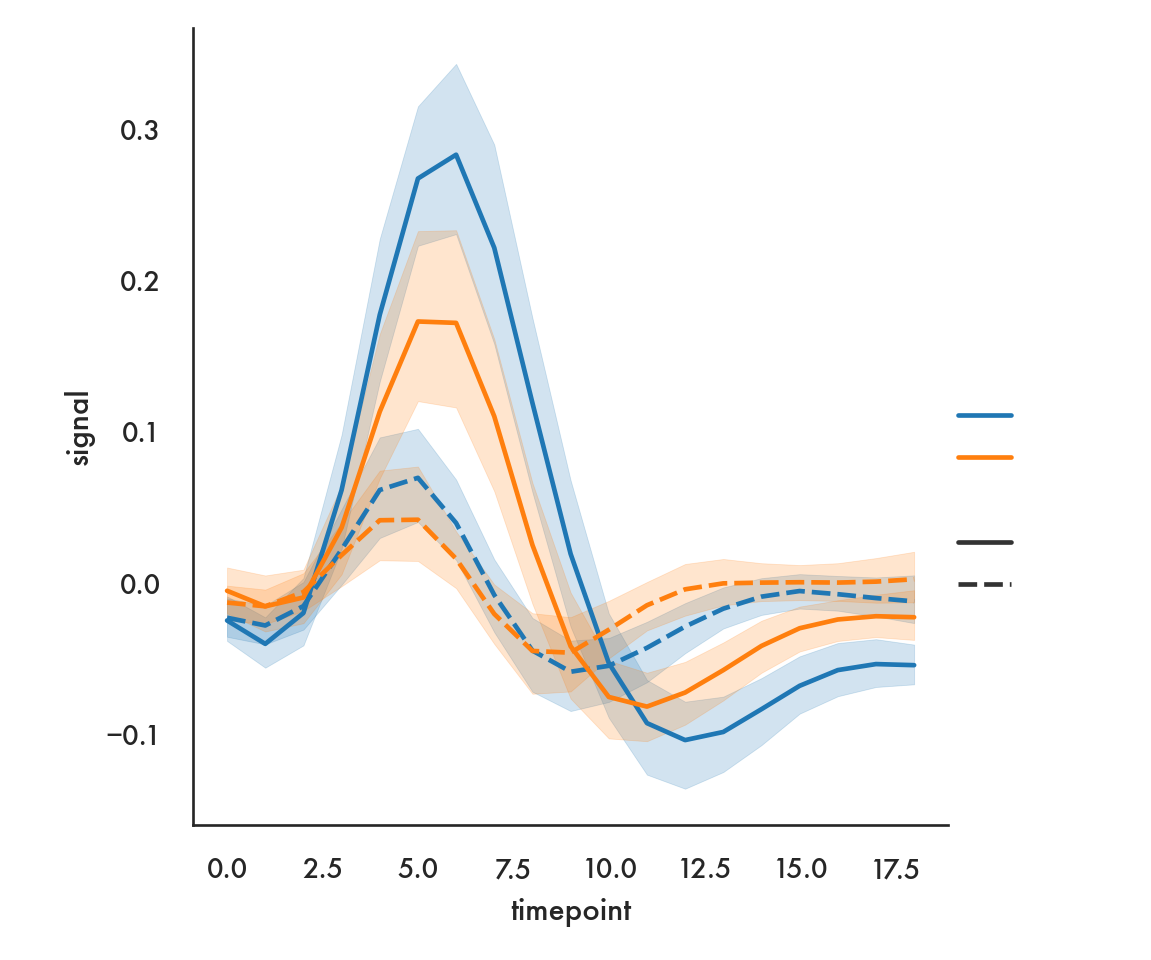
Here we use color to show the region, and line style (solid vs dashed) to show the event.
5.4.2.6 Scatter plots by group
g = sns.FacetGrid(diamonds, hue = 'color', height = 7.5)
g.map(plt.scatter, 'carat', 'price').add_legend();
plt.show()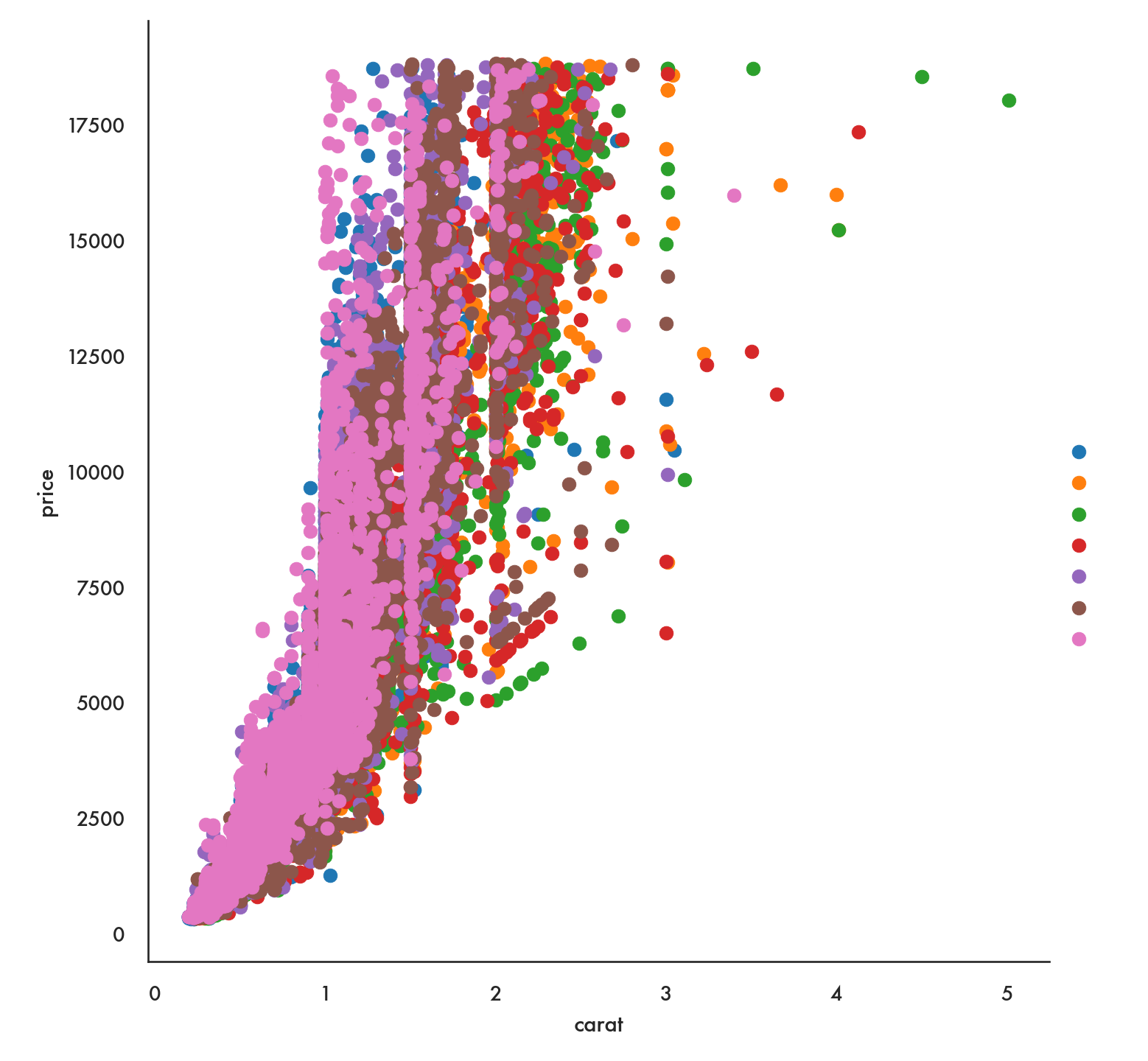
Notice that this arranges the colors and values for the color variable in random order. If we have a preferred order we can impose that using the option hue_order.
clarity_ranking = ["I1", "SI2", "SI1", "VS2", "VS1", "VVS2", "VVS1", "IF"]
sns.scatterplot(x="carat", y="price",
hue="clarity", size="depth",
hue_order=clarity_ranking,
sizes=(1, 8), linewidth=0,
data=diamonds);
plt.show() 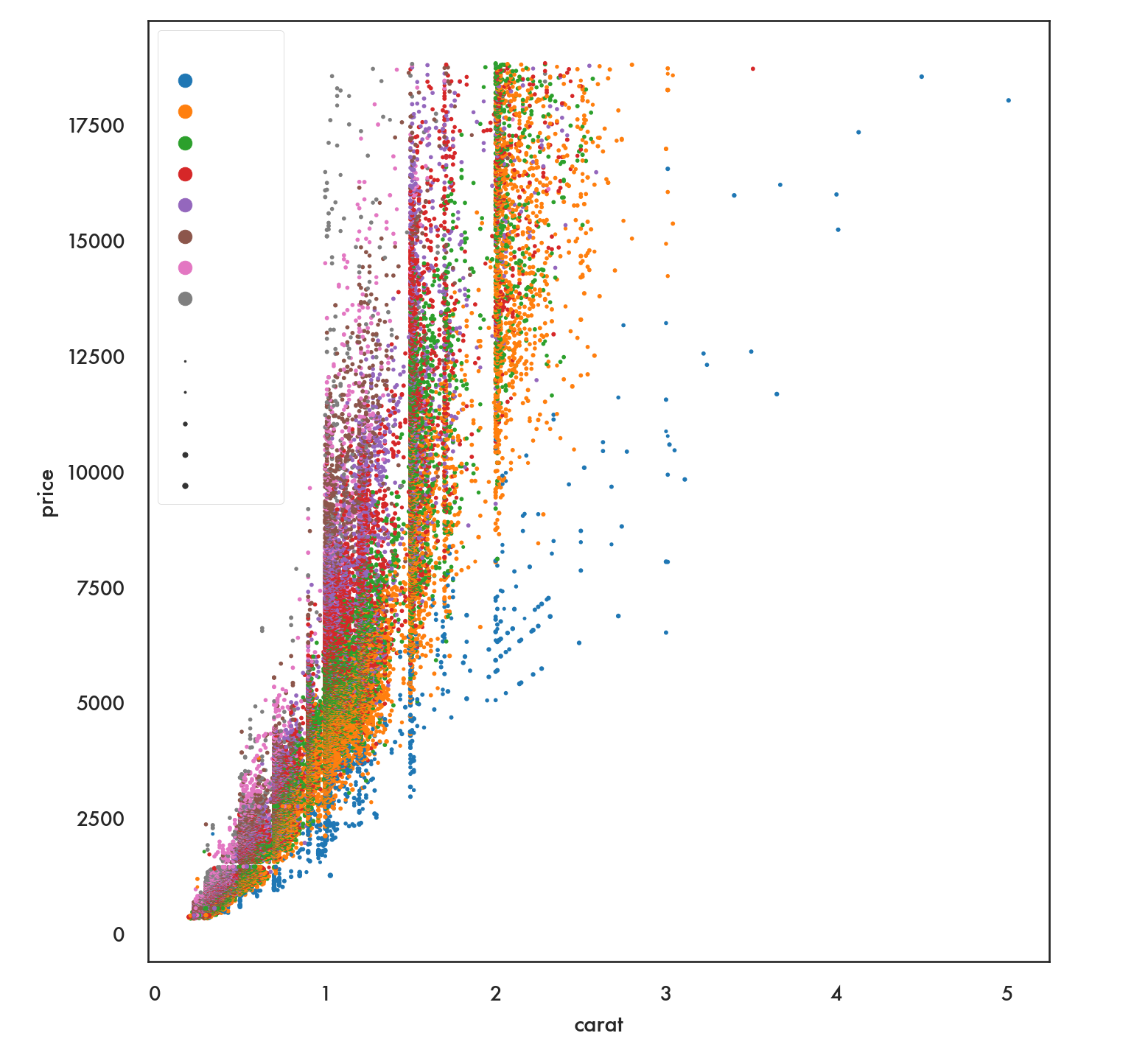
5.4.3 Facets
Facets or trellis graphics is a visualization method where we draw multiple plots in a grid, with each plot corresponding to unique values of a particular variable or combinations of variables. This has also been called small multiples.
We’ll proceed with an example using the iris dataset.
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5.0 3.6 1.4 0.2 setosag = sns.FacetGrid(iris, col = 'species', hue = 'species', height = 5)
g.map(plt.scatter, 'sepal_width', 'sepal_length').add_legend();
plt.show()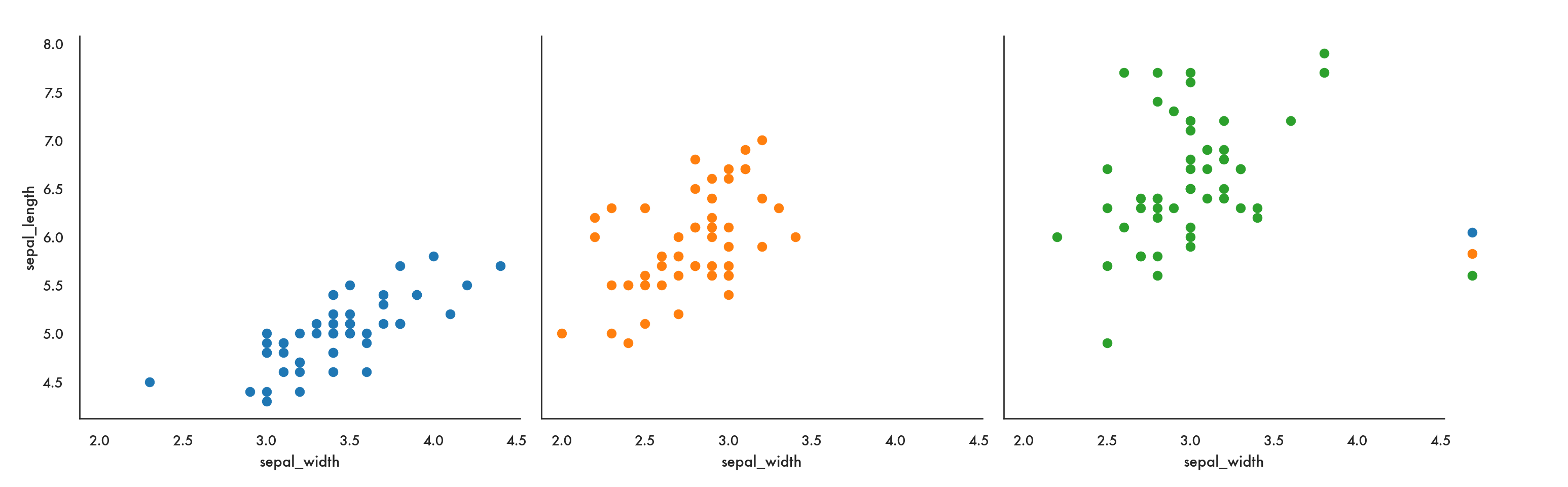
Here we use FacetGrid to indicate that we’re creating multiple subplots by specifying the option col (for column). So this code says we are going to create one plot per level of species, arranged as separate columns (or in effect along one row). You could also specify row which would arrange the plots one to a row, or, in effect, in one column.
The map function says, take the facets I’ve defined and stored in g, and in each one, plot a scatter plot with sepal_width on the x-axis and sepal_length on the y-axis.
We could also use relplot for a more compact solution.
sns.relplot(x = 'sepal_width', y = 'sepal_length', data = iris,
col = 'species', hue = 'species');
plt.show()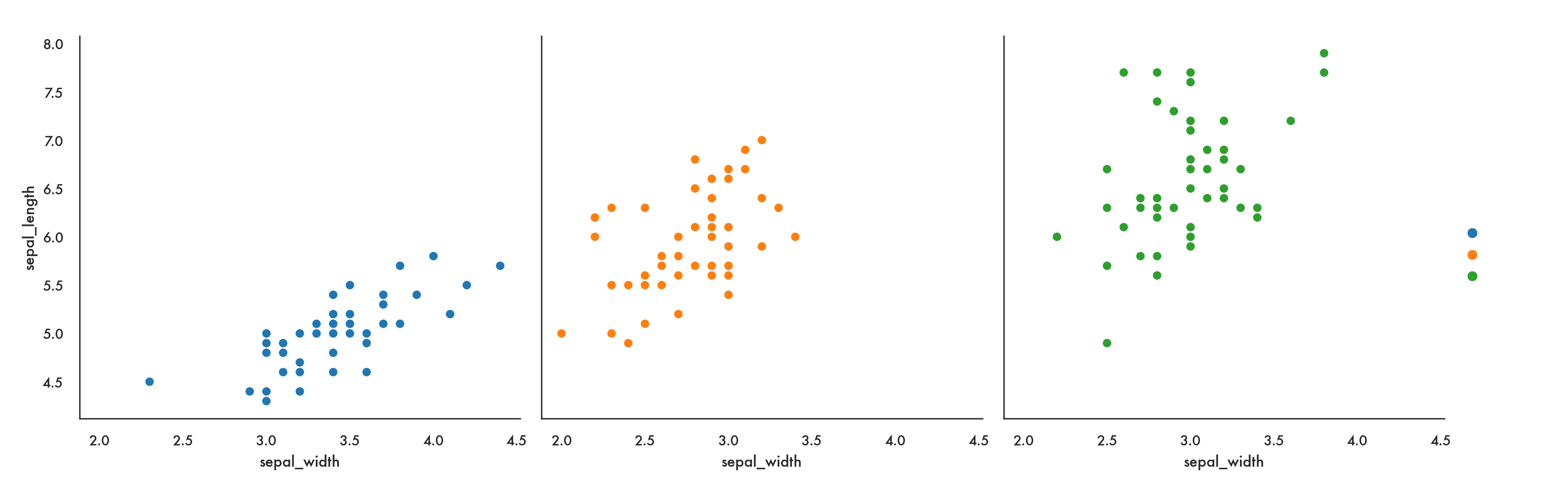
A bit more of a complicated example, using the fmri data, where we’re coloring lines based on the subject, and creating a 2-d grid, where region of the brain in along columns and event type is along rows.
sns.relplot(x="timepoint", y="signal", hue="subject",
col="region", row="event", height=3,
kind="line", estimator=None, data=fmri);/Users/abhijit/opt/miniconda3/envs/ds/lib/python3.8/site-packages/seaborn/axisgrid.py:324: RuntimeWarning: More than 20 figures have been opened. Figures created through the pyplot interface (`matplotlib.pyplot.figure`) are retained until explicitly closed and may consume too much memory. (To control this warning, see the rcParam `figure.max_open_warning`).
fig, axes = plt.subplots(nrow, ncol, **kwargs)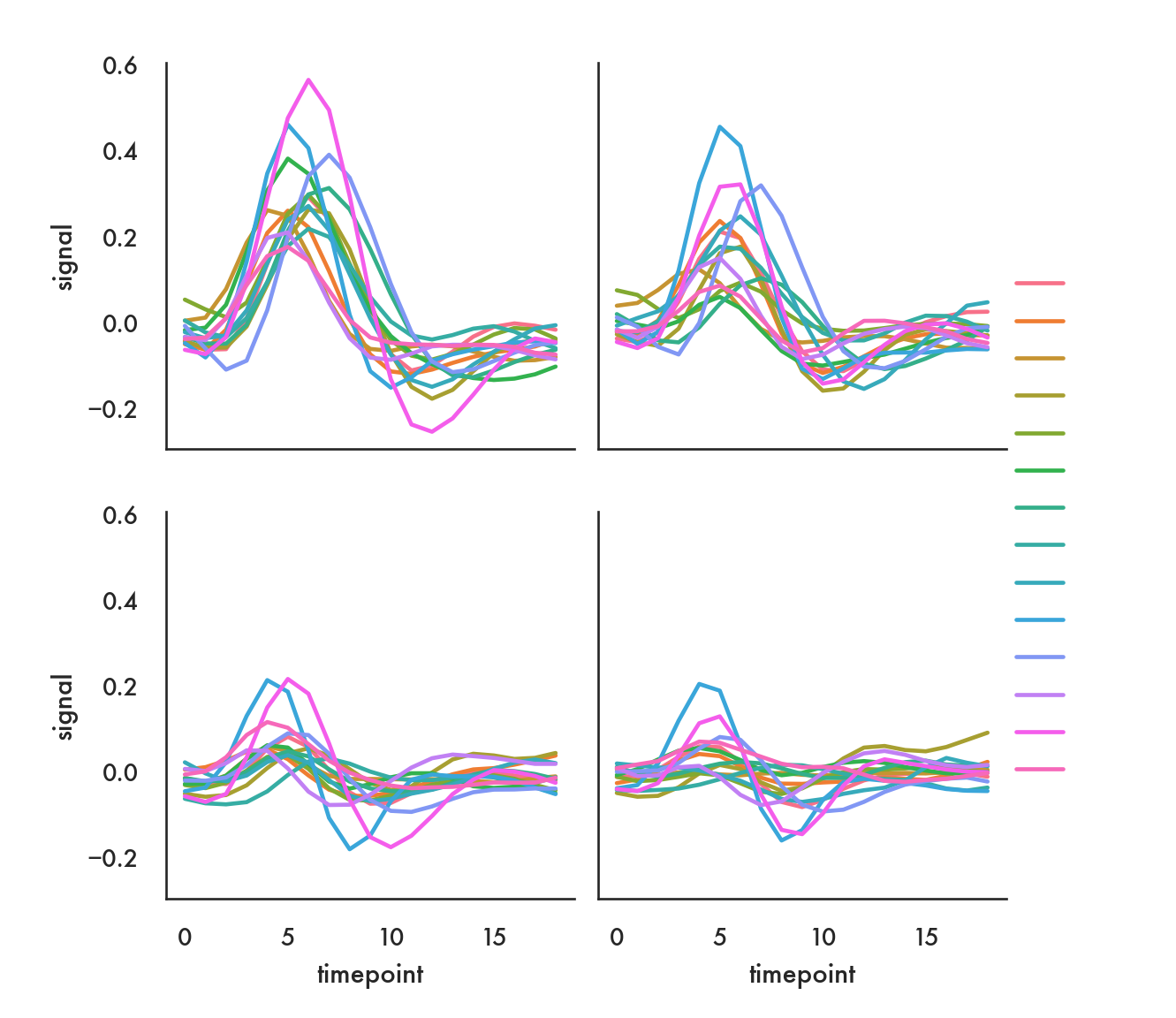
In the following example, we want to show how each subject fares for each of the two events, just within the frontal region. We let seaborn figure out the layout, only specifying that we’ll be going along rows (“by column”) and also saying we’ll wrap around to the beginning once we’ve got to 5 columns. Note we use the query function to filter the dataset.
sns.relplot(x="timepoint", y="signal", hue="event", style="event",
col="subject", col_wrap=5,
height=3, aspect=.75, linewidth=2.5,
kind="line", data=fmri.query("region == 'frontal'"));/Users/abhijit/opt/miniconda3/envs/ds/lib/python3.8/site-packages/seaborn/axisgrid.py:333: RuntimeWarning: More than 20 figures have been opened. Figures created through the pyplot interface (`matplotlib.pyplot.figure`) are retained until explicitly closed and may consume too much memory. (To control this warning, see the rcParam `figure.max_open_warning`).
fig = plt.figure(figsize=figsize)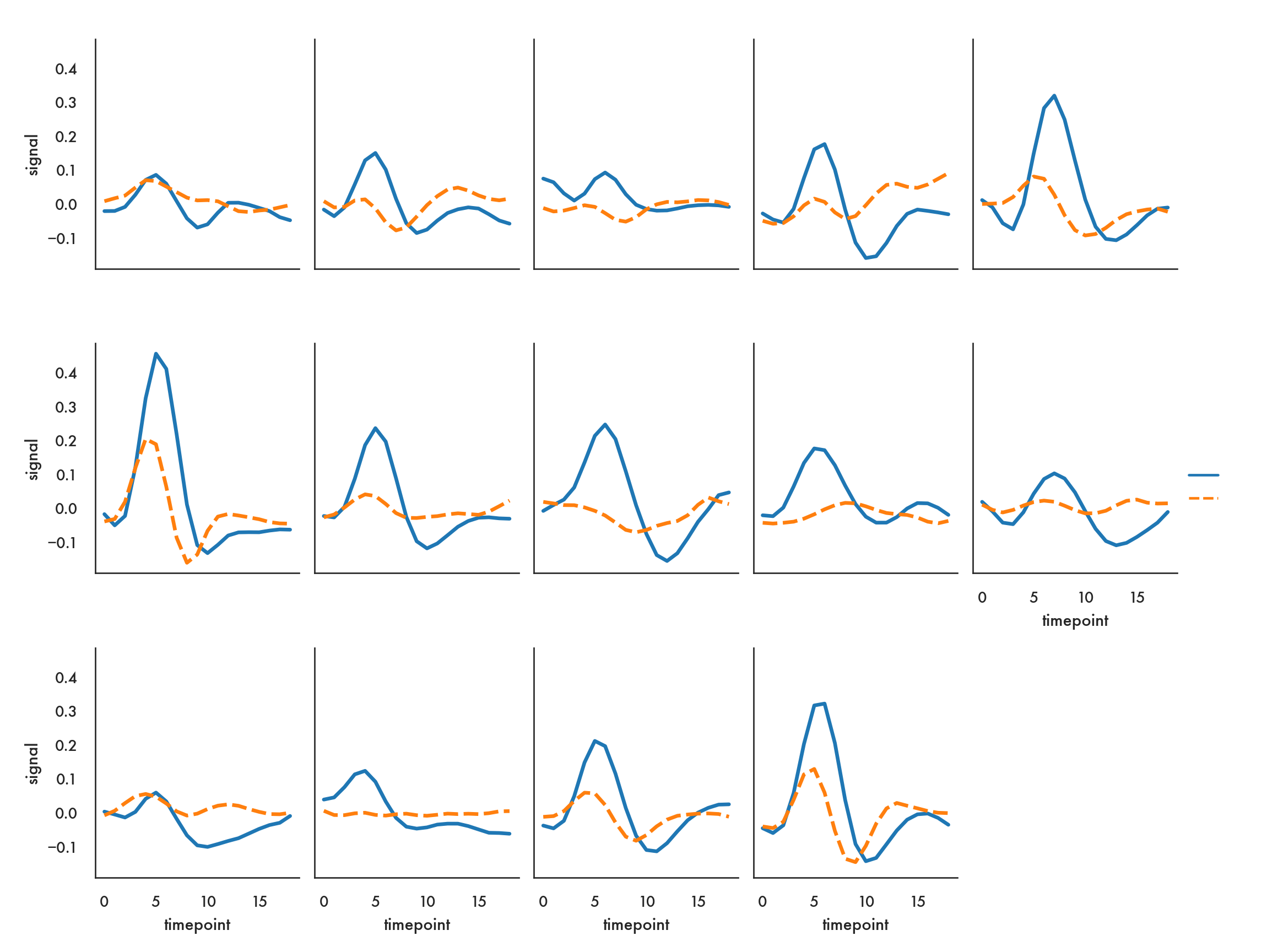
In the following example we want to compare the distribution of price from the diamonds dataset by color, and so it makes sense to create density plots of the price distribution and stack them one below the next so we can visually compare them.
ordered_colors = ['E','F','G','H','I','J']
g = sns.FacetGrid(data = diamonds, row = 'color', height = 1.7,
aspect = 4, row_order = ordered_colors)/Users/abhijit/opt/miniconda3/envs/ds/lib/python3.8/site-packages/seaborn/axisgrid.py:324: RuntimeWarning: More than 20 figures have been opened. Figures created through the pyplot interface (`matplotlib.pyplot.figure`) are retained until explicitly closed and may consume too much memory. (To control this warning, see the rcParam `figure.max_open_warning`).
fig, axes = plt.subplots(nrow, ncol, **kwargs)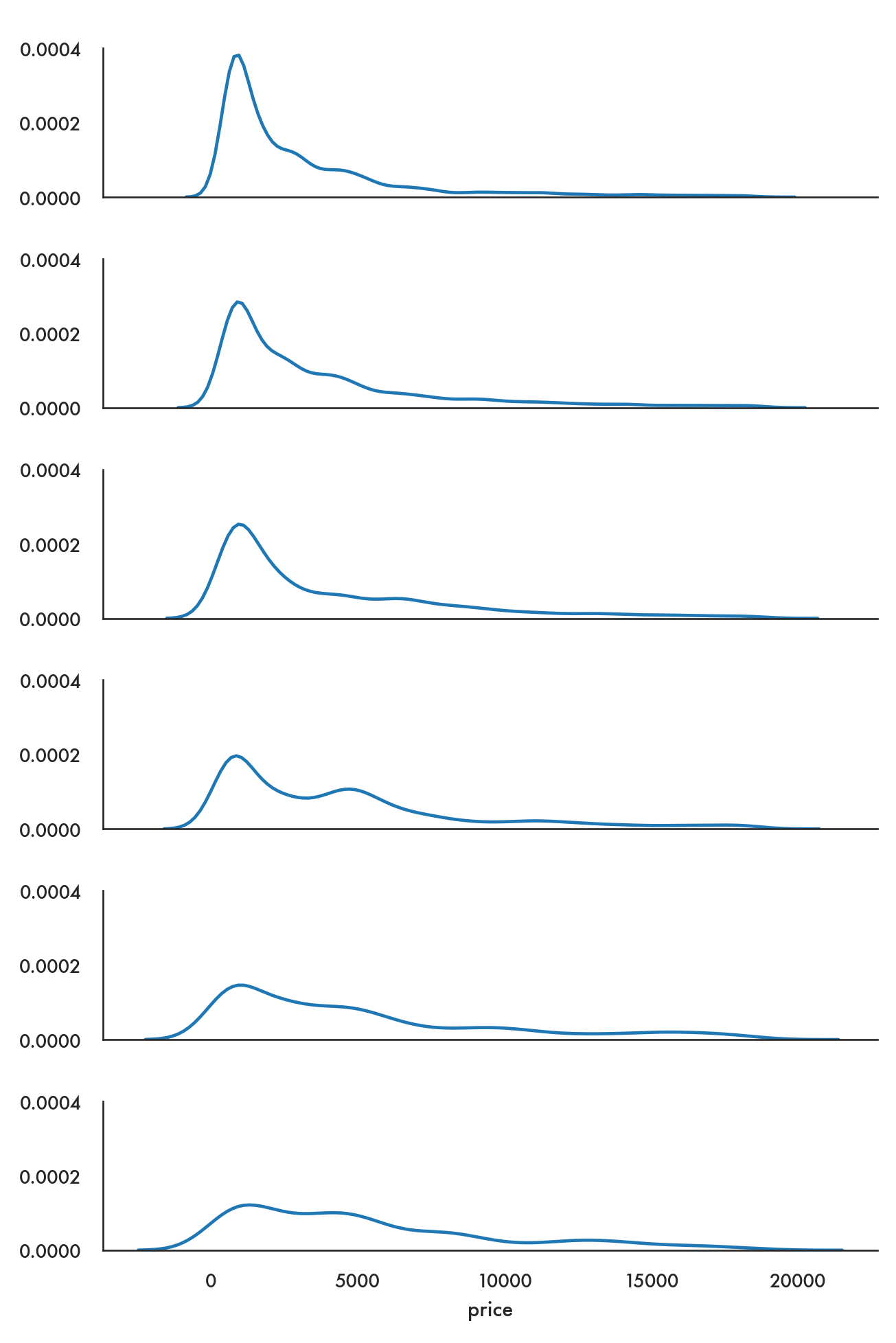
You need to use FacetGrid to create sets of univariate plots since there is no particular method that allows univariate plots over a grid like relplot for bivariate plots.
5.4.4 Pairs plots
The pairs plot is a quick way to compare every pair of variables in a dataset (or at least, every pair of continuous variables) in a grid. You can specify what kind of univariate plot will be displayed on the diagonal locations on the grid, and which bivariate plots will be displayed on the off-diagonal locations.
/Users/abhijit/opt/miniconda3/envs/ds/lib/python3.8/site-packages/seaborn/axisgrid.py:1292: RuntimeWarning: More than 20 figures have been opened. Figures created through the pyplot interface (`matplotlib.pyplot.figure`) are retained until explicitly closed and may consume too much memory. (To control this warning, see the rcParam `figure.max_open_warning`).
fig, axes = plt.subplots(len(y_vars), len(x_vars),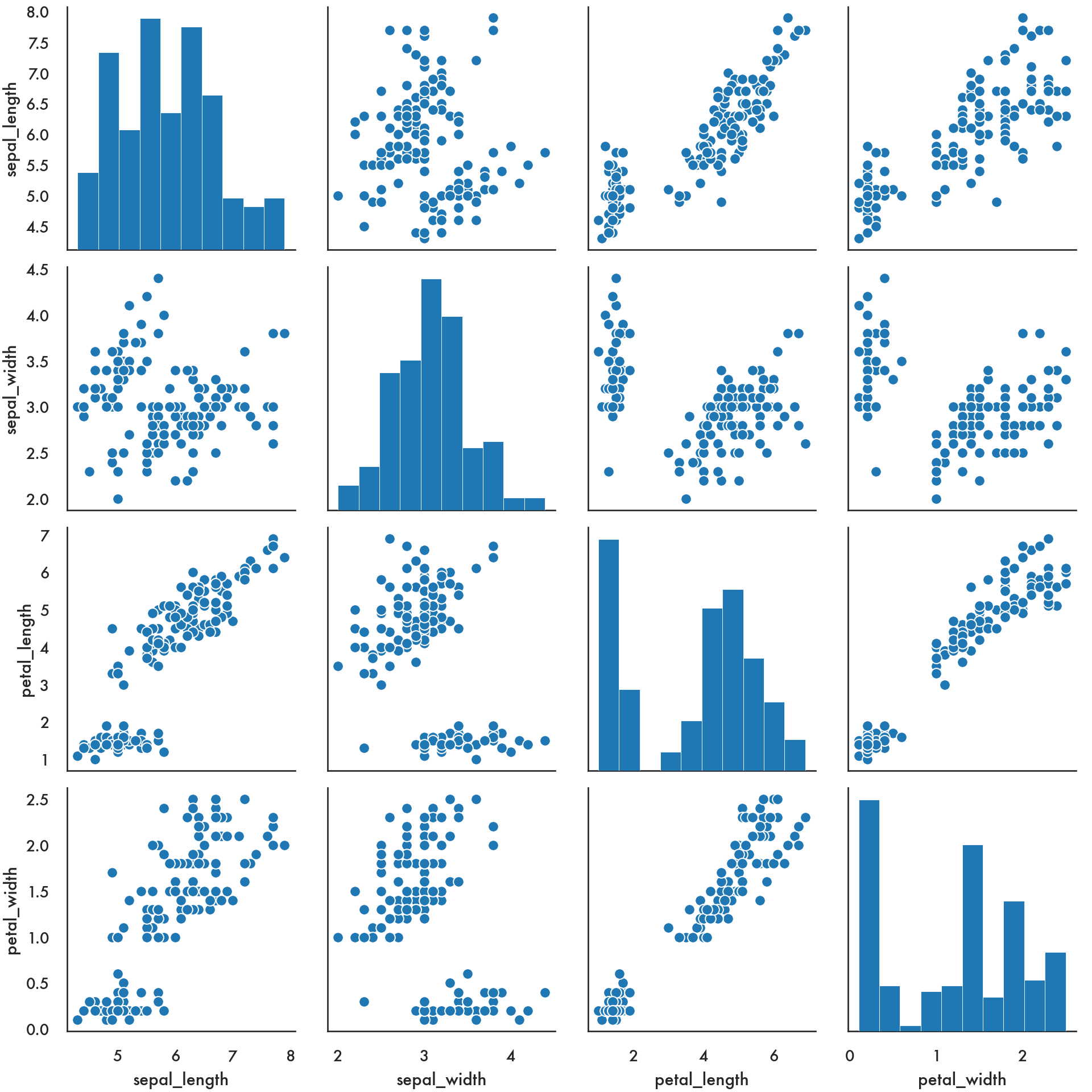
You can achieve more customization using PairGrid.
g = sns.PairGrid(iris, diag_sharey=False);
g.map_upper(sns.scatterplot);
g.map_lower(sns.kdeplot, colors="C0");
g.map_diag(sns.kdeplot, lw=2);
plt.show()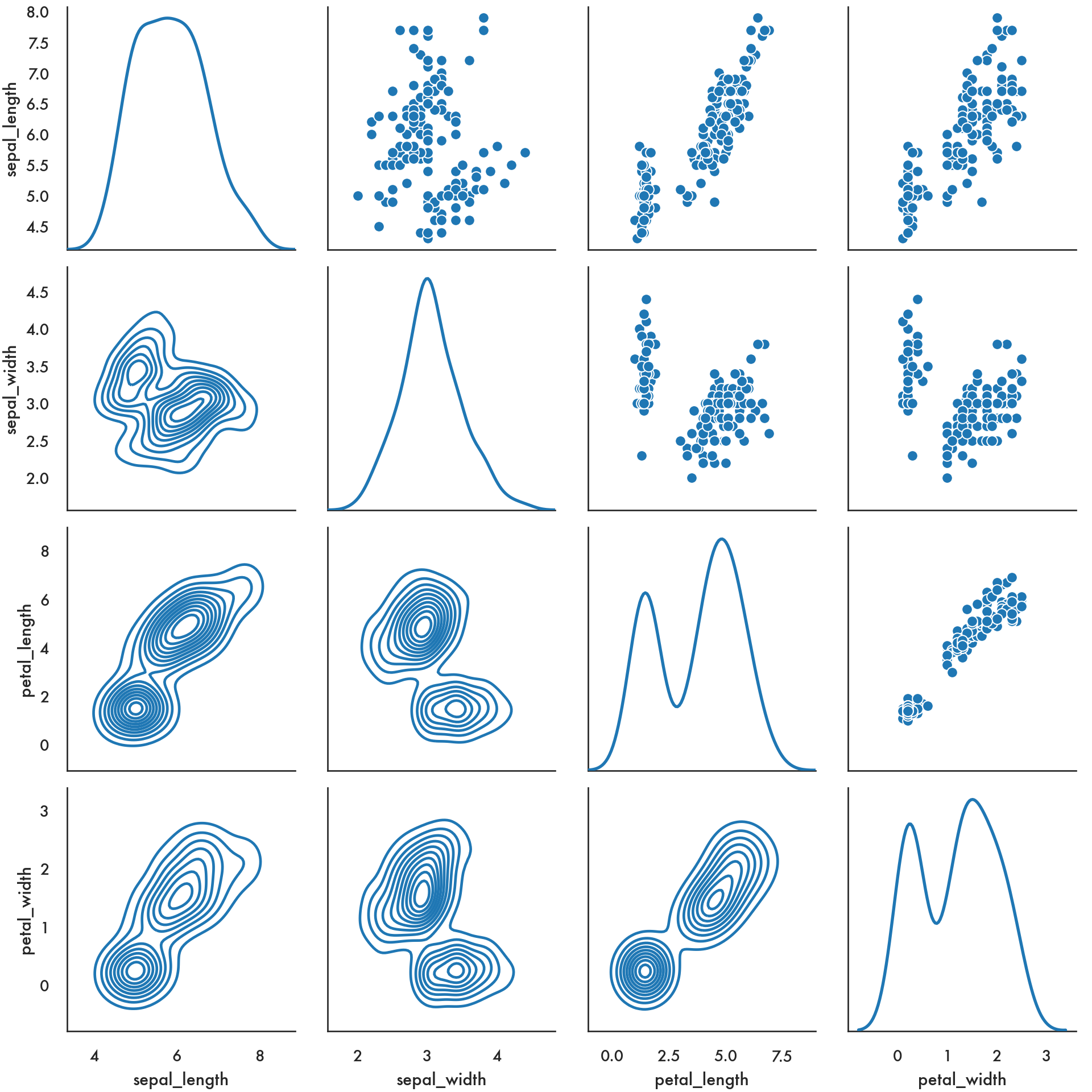
5.5 Customizing the look
5.5.1 Themes
There are several themes available in the modern matplotlib, some of which borrow from seaborn. You can see the available themes and play around.
['Solarize_Light2', '_classic_test_patch', 'bmh', 'classic', 'dark_background', 'fast', 'fivethirtyeight', 'ggplot', 'grayscale', 'seaborn', 'seaborn-bright', 'seaborn-colorblind', 'seaborn-dark', 'seaborn-dark-palette', 'seaborn-darkgrid', 'seaborn-deep', 'seaborn-muted', 'seaborn-notebook', 'seaborn-paper', 'seaborn-pastel', 'seaborn-poster', 'seaborn-talk', 'seaborn-ticks', 'seaborn-white', 'seaborn-whitegrid', 'tableau-colorblind10']See some examples below.
plt.style.use('fivethirtyeight')
sns.scatterplot(data = iris, x = 'sepal_width', y = 'sepal_length');
plt.show()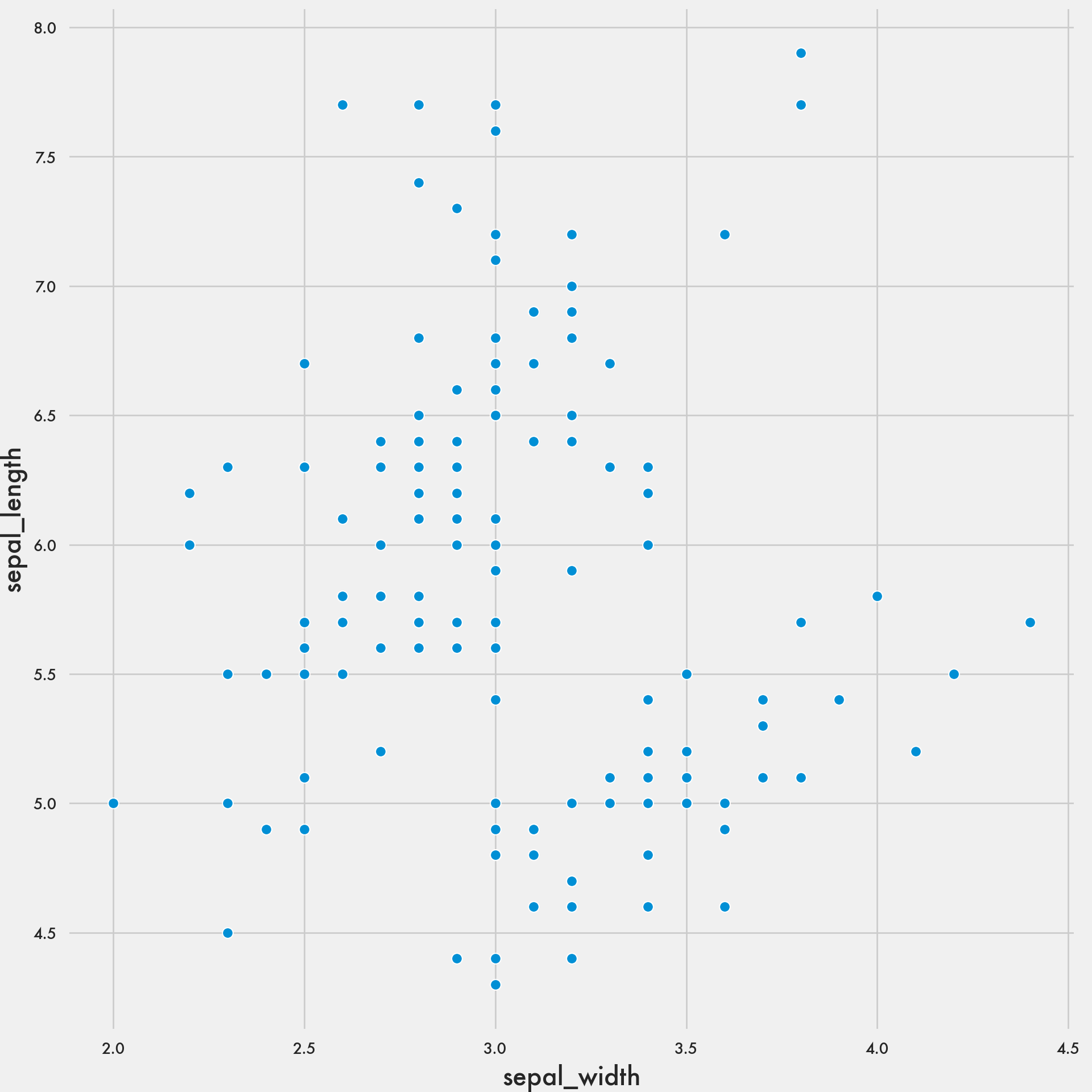
plt.style.use('bmh')
sns.scatterplot(data = iris, x = 'sepal_width', y = 'sepal_length');
plt.show()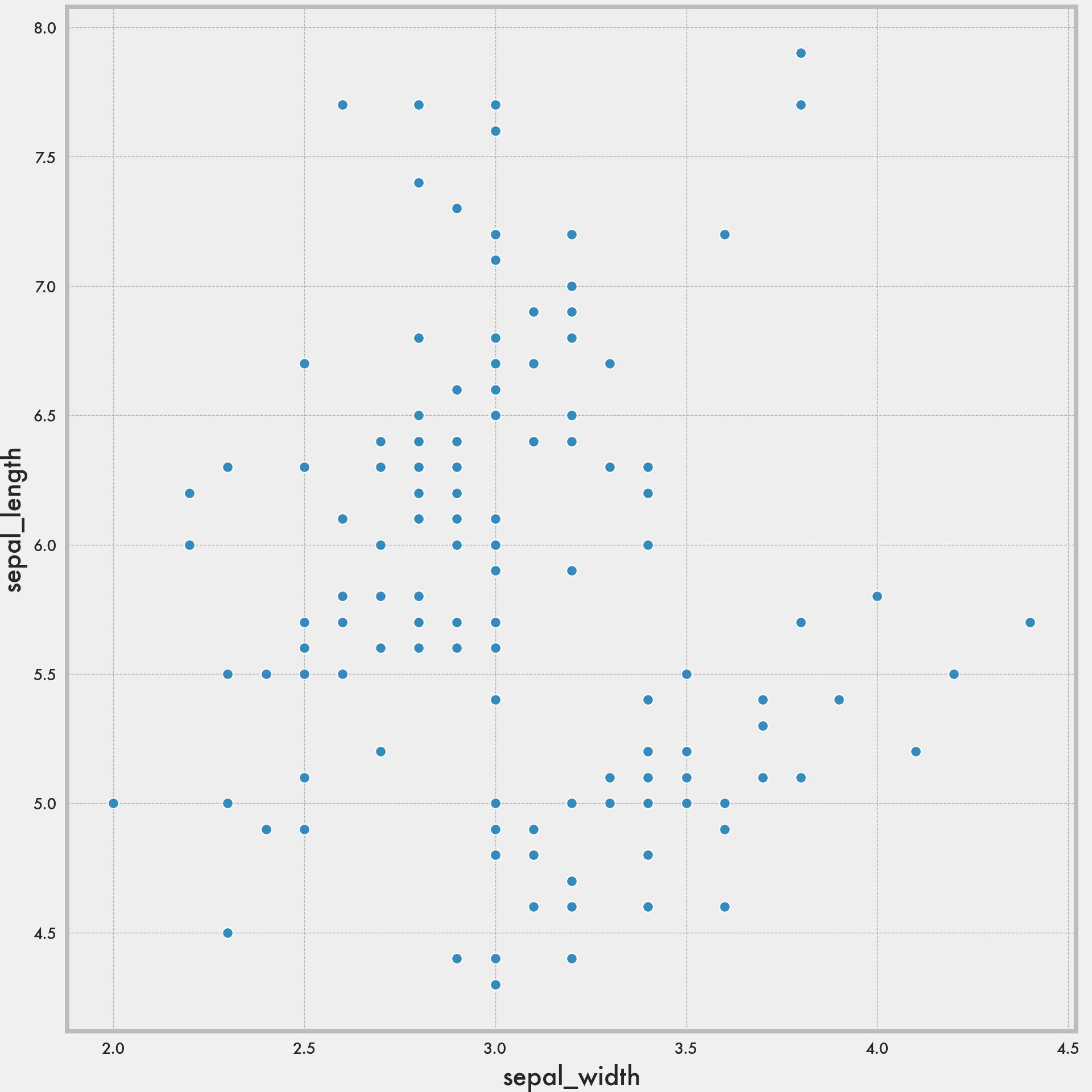
plt.style.use('classic')
sns.scatterplot(data = iris, x = 'sepal_width', y = 'sepal_length');
plt.show()
plt.style.use('ggplot')
sns.scatterplot(data = iris, x = 'sepal_width', y = 'sepal_length');
plt.show()
plt.style.use('Solarize_Light2')
sns.scatterplot(data = iris, x = 'sepal_width', y = 'sepal_length');
plt.show()
One small syntax point. You may have noticed in your own work that you get a little annoying line in the output when you plot. You can prevent that from happening by putting a semi-colon (
;) after the last plotting command
5.6 Finer control with matplotlib
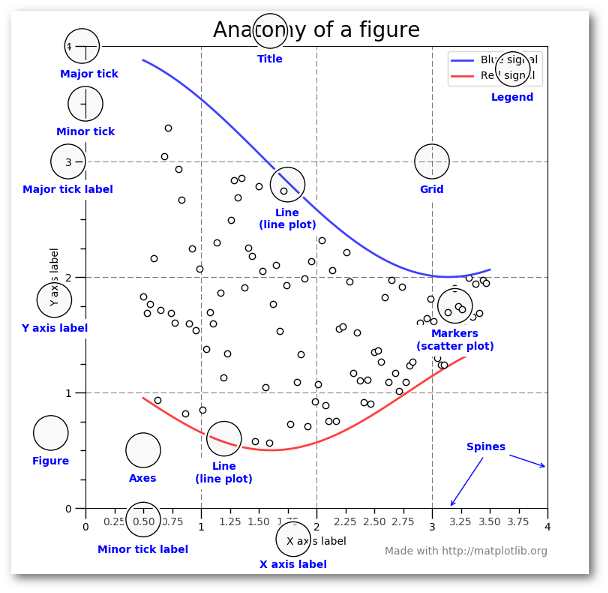
As you can see from the figure, you can control each aspect of the plot displayed above using matplotlib. I won’t go into the details, and will leave it to you to look at the matplotlib documentation and examples if you need to customize at this level of granularity.
The following is an example using pure matplotlib. You can see how you can build up a plot. The crucial part here is that you need to run the code from each chunk together.
from matplotlib.ticker import FuncFormatter
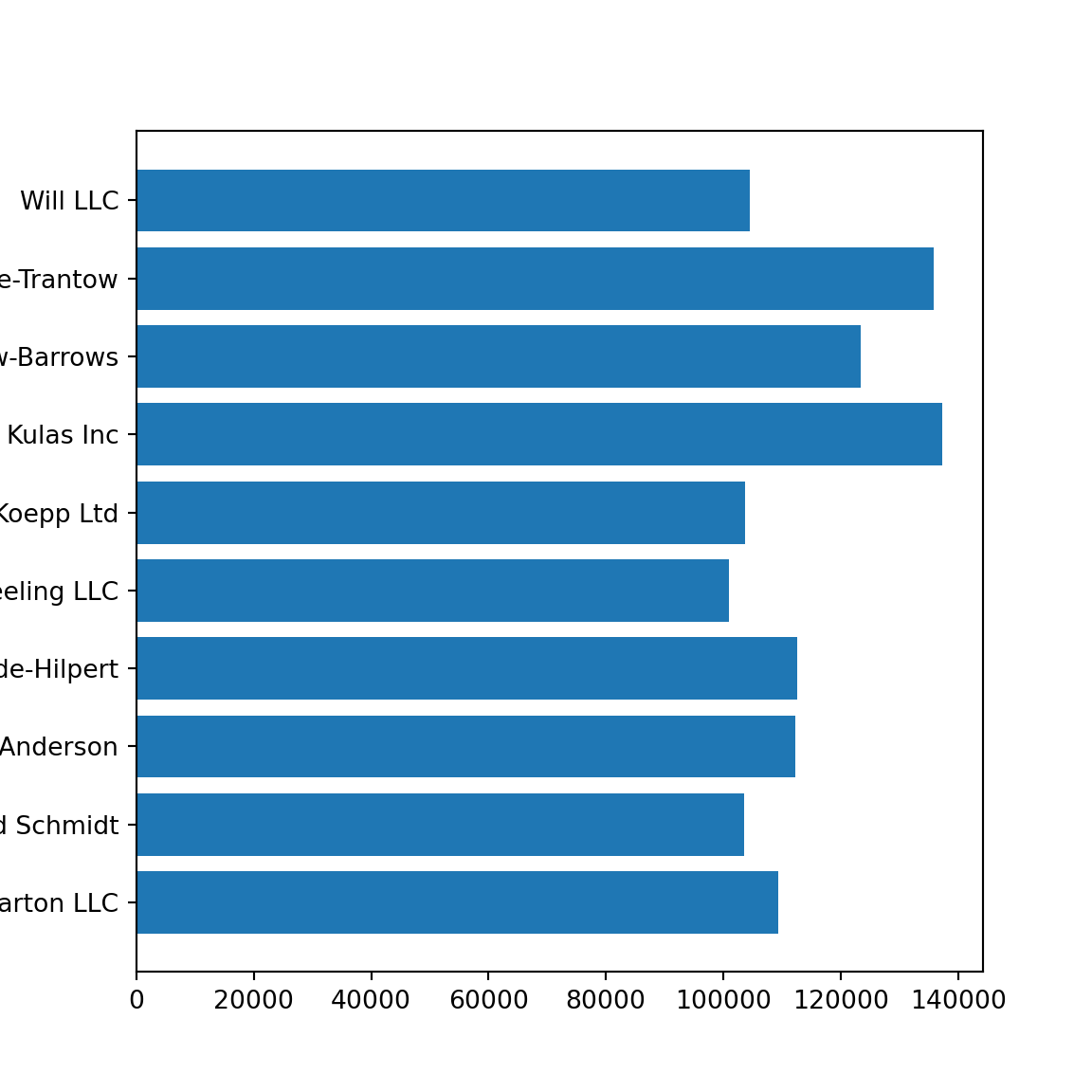
data = {'Barton LLC': 109438.50,
'Frami, Hills and Schmidt': 103569.59,
'Fritsch, Russel and Anderson': 112214.71,
'Jerde-Hilpert': 112591.43,
'Keeling LLC': 100934.30,
'Koepp Ltd': 103660.54,
'Kulas Inc': 137351.96,
'Trantow-Barrows': 123381.38,
'White-Trantow': 135841.99,
'Will LLC': 104437.60}
group_data = list(data.values())
group_names = list(data.keys())
group_mean = np.mean(group_data)<string>:1: RuntimeWarning: More than 20 figures have been opened. Figures created through the pyplot interface (`matplotlib.pyplot.figure`) are retained until explicitly closed and may consume too much memory. (To control this warning, see the rcParam `figure.max_open_warning`).
<BarContainer object of 10 artists>ax.set(xlim = [-10000, 140000], xlabel = 'Total Revenue', ylabel = 'Company',
title = 'Company Revenue');
plt.show()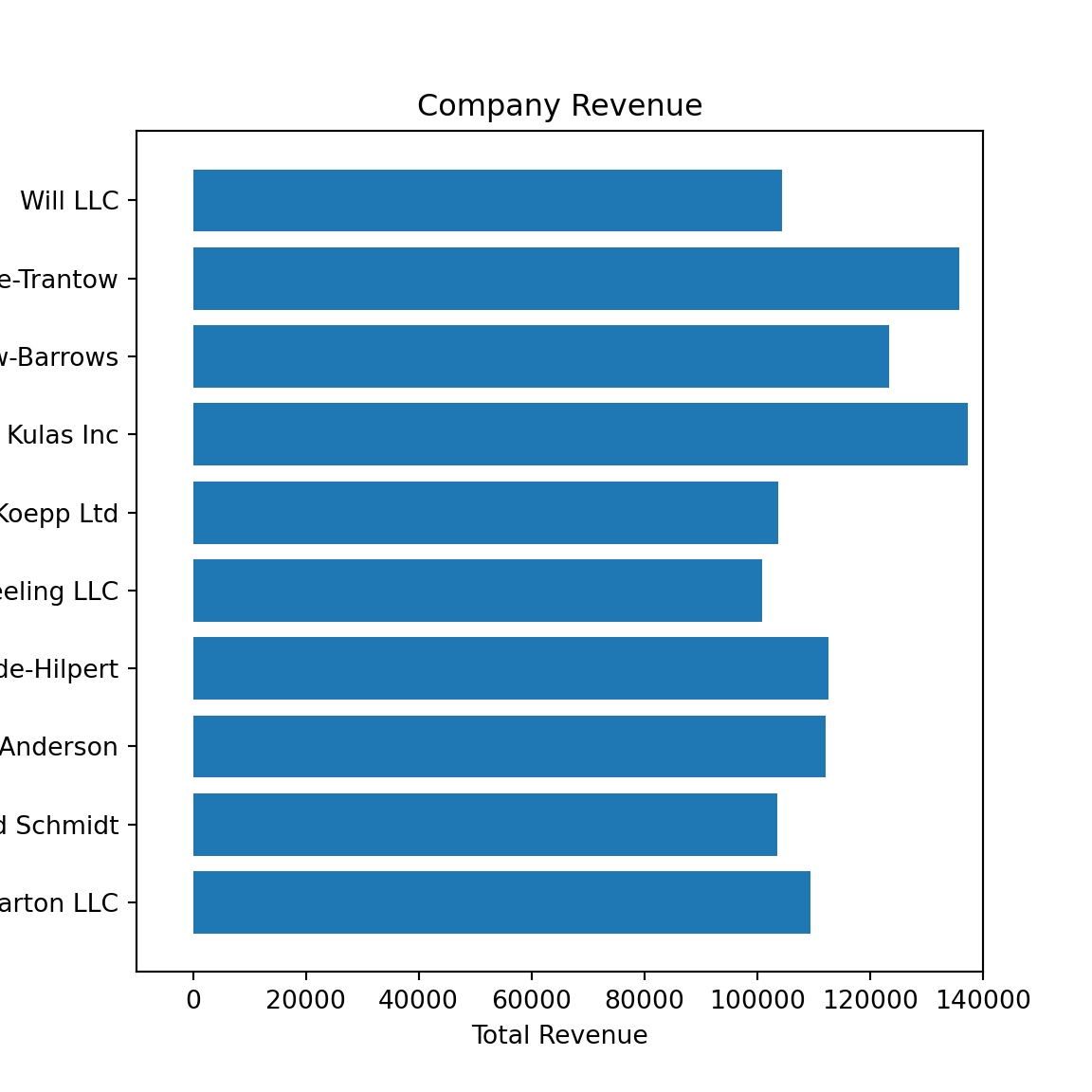
<BarContainer object of 10 artists>[None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None]ax.set(xlim=[-10000, 140000], xlabel='Total Revenue', ylabel='Company',
title='Company Revenue');
plt.show()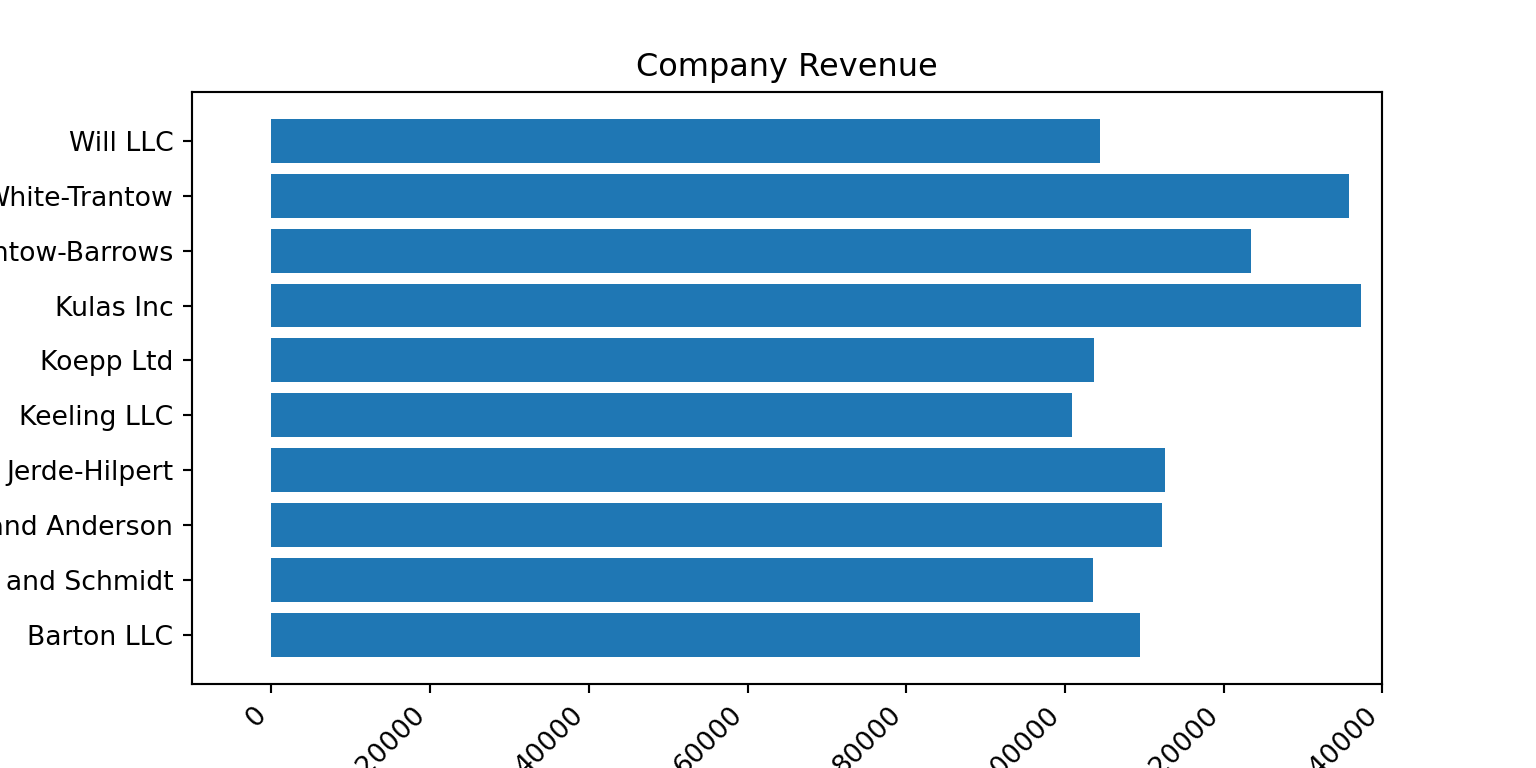
After you have created your figure, you do need to save it to disk so that you can use it in your Word or Markdown or PowerPoint document. You can see the formats available.
{'ps': 'Postscript', 'eps': 'Encapsulated Postscript', 'pdf': 'Portable Document Format', 'pgf': 'PGF code for LaTeX', 'png': 'Portable Network Graphics', 'raw': 'Raw RGBA bitmap', 'rgba': 'Raw RGBA bitmap', 'svg': 'Scalable Vector Graphics', 'svgz': 'Scalable Vector Graphics', 'jpg': 'Joint Photographic Experts Group', 'jpeg': 'Joint Photographic Experts Group', 'tif': 'Tagged Image File Format', 'tiff': 'Tagged Image File Format'}The type will be determined by the ending of the file name. You can add some options depending on the type. I’m showing an example of saving the figure to a PNG file. Typically I’ll save figures to a vector graphics format like PDF, and then convert into other formats, since that results in minimal resolution loss. You of course have the option to save to your favorite format.
5.6.1 Matlab-like plotting
matplotlib was originally developed to emulate Matlab. Though this kind of syntax is no longer recommended, it is still available and may be of use to those coming to Python from Matlab or Octave.
import numpy as np
# evenly sampled time at 200ms intervals
t = np.arange(0., 5., 0.2)
# red dashes, blue squares and green triangles
plt.plot(t, t, 'r--', t, t**2, 'bs', t, t**3, 'g^');
plt.show()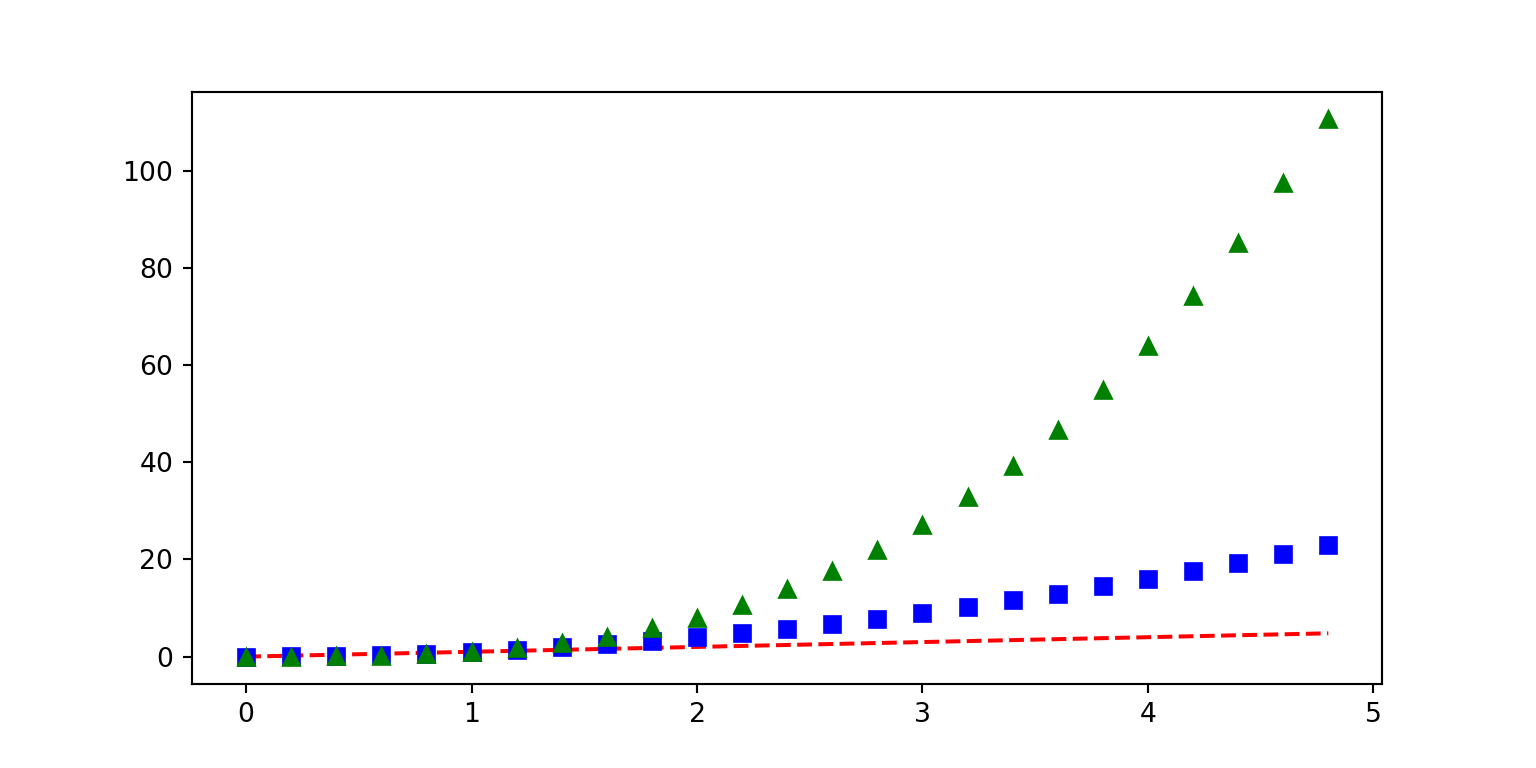
def f(t):
return np.exp(-t) * np.cos(2*np.pi*t)
t1 = np.arange(0.0, 5.0, 0.1)
t2 = np.arange(0.0, 5.0, 0.02)
plt.figure();<string>:1: RuntimeWarning: More than 20 figures have been opened. Figures created through the pyplot interface (`matplotlib.pyplot.figure`) are retained until explicitly closed and may consume too much memory. (To control this warning, see the rcParam `figure.max_open_warning`).plt.subplot(211);
plt.plot(t1, f(t1), 'bo', t2, f(t2), 'k');
plt.subplot(212);
plt.plot(t2, np.cos(2*np.pi*t2), 'r--');
plt.show()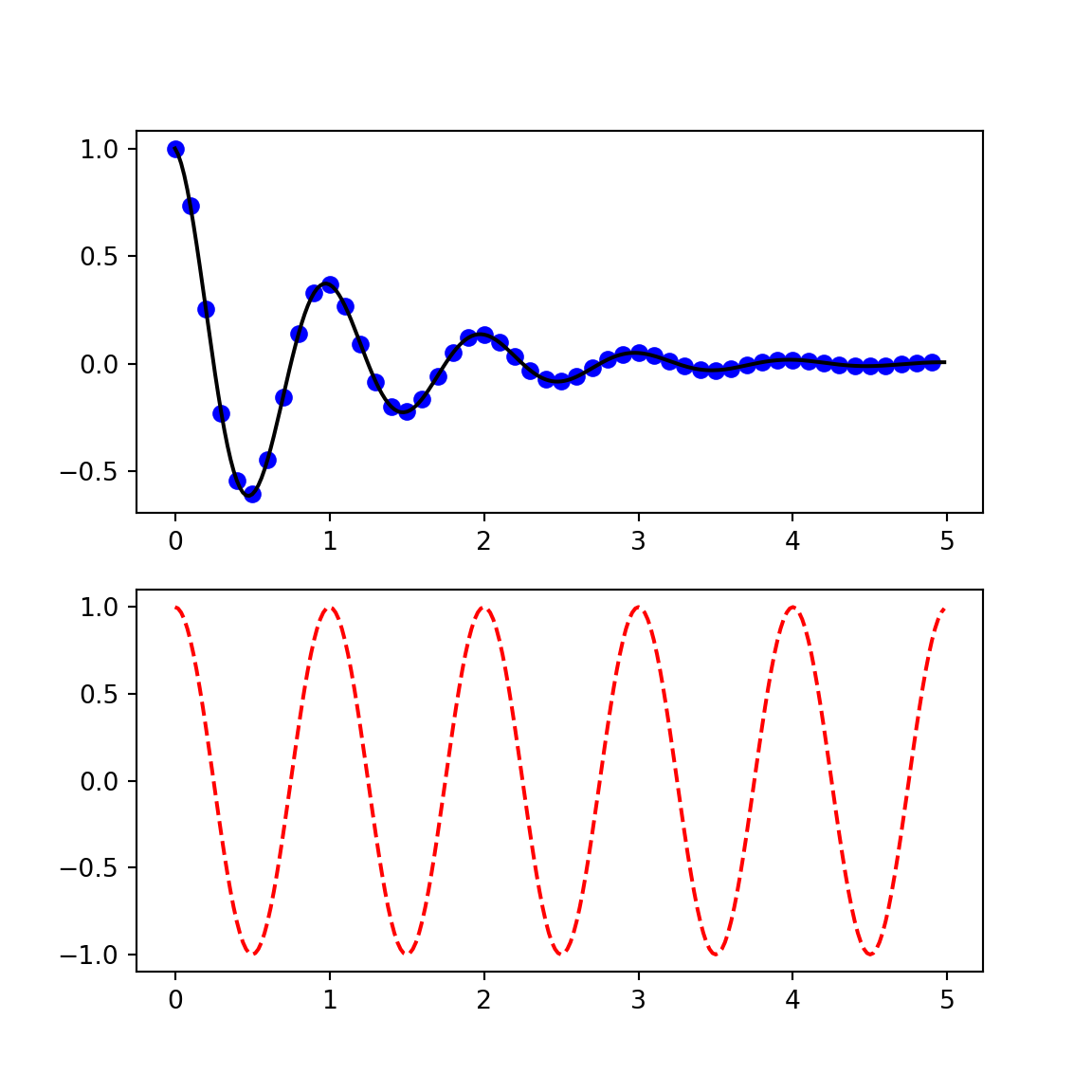
5.7 Resources
A really nice online resource for learning data visualization in Python is the Python Graph Gallery. This site has many examples of different kinds of plots using pandas, seaborn and matplotlib